ʲô��Selenium
Selenium��һ�����ڲ�����վ���Զ������Թ��ߣ�֧�ָ������������Chrome��Firefox��Safari�����������������ͬʱҲ֧��phantomJS�����������
1.������
����Selenium�Ļ������ù��̱ȽϷ������һᾡ������ϸ�Ķ�����н��⡣
1.1 ��װSelenium
����Selenium�Ļ������ù��̱ȽϷ������һ�һЩƪ��������н��⡣������cmd����������������ݰ�װSelenium�⡣
1.2 �����������װ
Selenium��ʹ�ñ�������Ӧ�������webdriver����Chrome�����Ϊ����������������Ӳ鿴�Լ����������Ӧ��Chromedriver�İ汾��
1.3 ������������
����������ĵ�ַ�dz��� ���ǿ����ֶ�����һ����������������Ŀ¼�� , �����ص�����������ļ�������Ŀ¼�¡�Ȼ�����ҵĵ��ԨC>���ԨC>ϵͳ���èC>���C>���������C>ϵͳ�����C>Path������Ŀ¼���ӵ�Path��ֵ�С�������ñ��������⣬���Բ����������
ע�⣬���ϵͳ����Ϊ��
selenium.common.exceptions.SessionNotCreatedException: Message: session not created:This version of ChromeDriver only supports Chrome version***
��ʾ��ǰ���ص�Chromedriver�İ汾���Լ�������İ汾����Ӧ������ͨ��Chrome�İ����鿴�Լ���������汾

1.4 С��ţ��
�������Ϳ��Բ������ǵ�selenium�Dz��ǿ�������ʹ���ˣ���һ�������ӿ�ʼ������������ٶȡ�
from selenium import webdriver
url='https://www.baidu.com/'
browser=webdriver.Chrome()
browser.get(url)
��������ﶼû������Ļ������Ѿ����Կ�ʼ������һ���ˡ�
2.��ز���
2.1 �������ģ��
���ȵ��뱾������������Ҫ����ؿ⣺
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
import time
����selenium.webdriver.common.by ��Ҫ������Ѱ��ҳԪ�ص�id��Ϣ�����ڶ�λ��ť�������֮���Ԫ�أ�WebDriverWait��Ҫ�����ڵȴ���ҳ��Ӧ��ɣ���Ϊ��ҳû����ȫ���أ���ʹ��find_elements_by_**�ȷ������ͻ�����Ҳ�����ӦԪ�ص������
2.2 ��ȡ��Ϣ
movies=browser.find_elements_by_class_name('movie-name-text')
names=[]
for item in movies:
if item.text!='':
names.append(item.text)
����find_elements_by_class_name����ͨ������class_name������ӰƬ���������Ϣ��
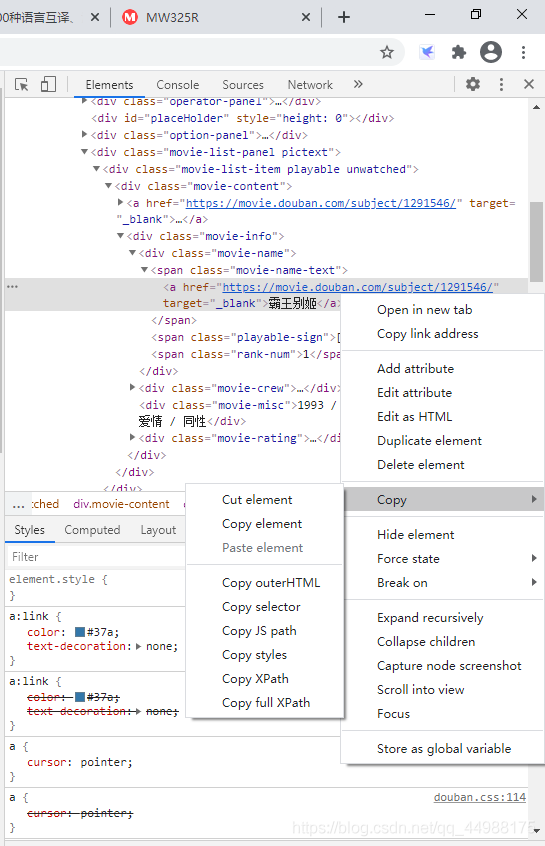
���Ԫ�غ��Ҽ�����Copy���Ԫ�ص�JS path��selector����Ϣ�������������Ԫ�ؼ������Ƶ�����Ԫ�ص���Ϣ���ԡ�������'�ⲿӰƬΪ��������selector����#content > div > div.article > div.movie-list-panel.pictext > div:nth-child(1) > div > div > div.movie-name > span.movie-name-text > a
��ô�Ϳ���������Ĵ���������ӰƬ���ơ�
movies=browser.find_elements_by_class_name('#content > div > div.article > div.movie-list-panel.pictext > div:nth-child(1) > div > div > div.movie-name > span.movie-name-text > a')
2.3 ���õȴ�ʱ��
ǰ���Ѿ�˵�������ҳ�滹û����ȫ���س������Ǿͽ���Ԫ�صIJ��ң����صĺܿ����ǿ��б�������������Ҫ���õȴ�ʱ�䡣
������漰����ʾ�ȴ�����ʽ�ȴ�������
2.3.1 ��ʽ�ȴ�
ÿ��һ��ʱ����һ�ε�ǰҳ��Ԫ���Ƿ���ڣ������������ʱ���ⲻ�����׳��쳣��TimeoutException�������ʽ��WebDriverWait(driver, timeout, poll_frequency=0.5, ignored_exceptions=None)
2.3.2 ��ʽ�ȴ�
��ʽ�ȴ���ͨ��һ����ʱ���ȴ�ҳ����ij��Ԫ�ؼ�����ɡ�������������õ�ʱ��Ԫ�ػ�û�б����أ����׳�NoSuchElementException�쳣��
�������£�implicitly_wait()
��ʹ������ʽ�ȴ�ִ�в��Ե�ʱ����� WebDriverû���� DOM���ҵ�Ԫ�أ��������ȴ��������趨ʱ������׳��Ҳ���Ԫ�ص��쳣���仰˵��������Ԫ�ػ�Ԫ�ز�û���������ֵ�ʱ����ʽ�ȴ����ȴ�һ��ʱ���ٲ��� DOM��Ĭ�ϵ�ʱ����0��һ����������ʽ�ȴ��������������� WebDriver ����ʵ�������������У���ʽ�ĵȵ�����һ��������Ӧ��Ӧ�õIJ��Ա�������������Ѱ��ÿ��Ԫ�ص�ʱ���еȴ���������������������ִ�е�ʱ�䡣��������ʹ�õľ�����ʽ�ȴ���
def get_page():
browser.implicitly_wait(10)
for i in range(50):
time.sleep(0.3)
browser.execute_script('window.scrollTo(0,document.body.scrollHeight)')
print('�����»���{}��'.format(i))
print('-------------')
#time.sleep(10)
print("*****��ȴ�����*****")
time.sleep(10)
when=wait.until(EC.presence_of_all_elements_located((By.CSS_SELECTOR,'#content > div > div.article > div.movie-list-panel.pictext > div:nth-child(380) > div > a > img')))
2.3.3 ǿ�Ƶȴ������䣩
ǿ�Ƶȴ�����ʹ��python�Դ���timeģ�飬���õȴ�ʱ�䣬�������£�time.sleep(time)һ�������ǿ�Ƶȴ������Ƽ����Ƶ������Ŀ�����ӵ�����֤���⡣
2.4 ҳ���Զ��»�
ҳ���»����̱Ƚϼ�����������ʵ�ֹ������£�
browser.execute_script('window.scrollTo(0,document.body.scrollHeight)')#�»�����
2.5 �����ļ�
��ȡ�����������б���ʽ��ʹ��pandas��to_csv�����Ϳ��Ա��浽�����ˡ�
rate,miscs,actor_list,ranks,playable_sign,names=get_page()
datas=pd.DataFrame({'names':names,'rank':ranks,'����':miscs,'����':rate})
try:
datas.to_csv('����ѧϰ\����\douban_0327.csv',encoding='utf_8_sig')
print("����ɹ�")
print(datas)
3.��������
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
import pandas as pd
import time
url='https://movie.douban.com/typerank?type_name=����Ƭ&type=13&interval_id=100:90&action='
options=webdriver.ChromeOptions()
options.add_argument('lang=zh_CN.UTF-8')
options.add_argument('user-agent="Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36"')
browser=webdriver.Chrome()
browser.get(url)
wait=WebDriverWait(browser,10)
def get_page():
browser.implicitly_wait(10)
for i in range(50):
time.sleep(0.3)
browser.execute_script('window.scrollTo(0,document.body.scrollHeight)')#�»�����
print('�����»���{}��'.format(i))
print('-------------')
#time.sleep(10)
print("*****��ȴ�����*****")
time.sleep(10)
when=wait.until(EC.presence_of_all_elements_located((By.CSS_SELECTOR,'#content > div > div.article > div.movie-list-panel.pictext > div:nth-child(380) > div > a > img')))
#-----------------------------------------------------------------
movies=browser.find_elements_by_class_name('movie-name-text')
names=[]
for item in movies:
if item.text!='':
names.append(item.text)
print("��ȡ�ɹ�")
print(len(names))
#---------------------------------------------------------------
playables=browser.find_elements_by_class_name('playable-sign')
playable_sign=[]
for sign in playables:
if sign.text!='':
playable_sign.append(sign.text)
print('��ȡ�ɹ�')
print(len(playable_sign))
#------------------------------------------------------------
rank_names=browser.find_elements_by_class_name('rank-num')
ranks=[]
for rank in rank_names:
if rank.text!='':
ranks.append(rank.text)
print('��ȡ�ɹ�')
print(len(ranks))
#---------------------------------------------------------
actors=browser.find_elements_by_class_name('movie-crew')
actor_list=[]
for actor in actors:
if actor.text!='':
actor_list.append(actor.text)
print('��ȡ�ɹ�')
print(len(actor_list))
#----------------------------------------------------------
clasic=browser.find_elements_by_class_name('movie-misc')
miscs=[]
for misc in clasic:
if misc.text!='':
miscs.append(misc.text)
print('��ȡ�ɹ�')
print(len(miscs))
#-----------------------------------------------------------
rates=browser.find_elements_by_class_name('movie-rating')
rate=[]
for score in rates:
if score.text!='':
rate.append(score.text)
print('��ȡ�ɹ�')
print(len(rate))
#-----------------------------------------------------------
'''
links=browser.find_elements_by_class_name('movie-content')
for link in links:
link_img=link.get_attribute('data-original')
print(link_img)
'''
return rate,miscs,actor_list,ranks,playable_sign,names
if __name__ == "__main__":
rate,miscs,actor_list,ranks,playable_sign,names=get_page()
datas=pd.DataFrame({'names':names,'rank':ranks,'����':miscs,'����':rate})
try:
datas.to_csv('����ѧϰ\����\douban_0327.csv',encoding='utf_8_sig')
print("����ɹ�")
print(datas)
except:
print('����ʧ��')
js