/**
* The {@code String} class represents character strings. All
* string literals in Java programs, such as {@code "abc"}, are
* implemented as instances of this class.
* <p>
* Strings are constant; their values cannot be changed after they
* are created. String buffers support mutable strings.
* Because String objects are immutable they can be shared. For example:
* <blockquote><pre>
* String str = "abc";
* </pre></blockquote><p>
* is equivalent to:
* <blockquote><pre>
* char data[] = {'a', 'b', 'c'};
* String str = new String(data);
* </pre></blockquote><p>
* Here are some more examples of how strings can be used:
* <blockquote><pre>
* System.out.println("abc");
* String cde = "cde";
* System.out.println("abc" + cde);
* String c = "abc".substring(2,3);
* String d = cde.substring(1, 2);
* </pre></blockquote>
* <p>
* The class {@code String} includes methods for examining
* individual characters of the sequence, for comparing strings, for
* searching strings, for extracting substrings, and for creating a
* copy of a string with all characters translated to uppercase or to
* lowercase. Case mapping is based on the Unicode Standard version
* specified by the {@link java.lang.Character Character} class.
* <p>
* The Java language provides special support for the string
* concatenation operator ( + ), and for conversion of
* other objects to strings. For additional information on string
* concatenation and conversion, see <i>The Java™ Language Specification</i>.
*
* <p> Unless otherwise noted, passing a {@code null} argument to a constructor
* or method in this class will cause a {@link NullPointerException} to be
* thrown.
*
* <p>A {@code String} represents a string in the UTF-16 format
* in which <em>supplementary characters</em> are represented by <em>surrogate
* pairs</em> (see the section <a href="Character.html#unicode">Unicode
* Character Representations</a> in the {@code Character} class for
* more information).
* Index values refer to {@code char} code units, so a supplementary
* character uses two positions in a {@code String}.
* <p>The {@code String} class provides methods for dealing with
* Unicode code points (i.e., characters), in addition to those for
* dealing with Unicode code units (i.e., {@code char} values).
*
* <p>Unless otherwise noted, methods for comparing Strings do not take locale
* into account. The {@link java.text.Collator} class provides methods for
* finer-grain, locale-sensitive String comparison.
*
* @implNote The implementation of the string concatenation operator is left to
* the discretion of a Java compiler, as long as the compiler ultimately conforms
* to <i>The Java™ Language Specification</i>. For example, the {@code javac} compiler
* may implement the operator with {@code StringBuffer}, {@code StringBuilder},
* or {@code java.lang.invoke.StringConcatFactory} depending on the JDK version. The
* implementation of string conversion is typically through the method {@code toString},
* defined by {@code Object} and inherited by all classes in Java.
*
* @author Lee Boynton
* @author Arthur van Hoff
* @author Martin Buchholz
* @author Ulf Zibis
* @see java.lang.Object#toString()
* @see java.lang.StringBuffer
* @see java.lang.StringBuilder
* @see java.nio.charset.Charset
* @since 1.0
* @jls 15.18.1 String Concatenation Operator +
*/
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
}
(3)方法上常用文档标记
-
@param:该文档标记后面写方法的参数名,再写参数描述。
/**
* @param str
* the {@code CharSequence} to check (may be {@code null})
*/
public static boolean containsWhitespace(@Nullable CharSequence str) {}
-
@return:该文档标记后面写返回值得描述。
/**
* @return {@code true} if the {@code String} is not {@code null}, its
*/
public static boolean hasText(@Nullable String str){}
-
@throws:该文档标记后面写异常的类型和异常的描述,用于描述该方法可能抛出的异常。
/**
* @throws IllegalArgumentException when the given source contains invalid encoded sequences
*/
public static String uriDecode(String source, Charset charset){}
-
@exception:该标注用于描述方法签名throws对应的异常。
/**
* @exception IllegalArgumentException if <code>key</code> is null.
*/
public static Object get(String key) throws IllegalArgumentException {}
-
@see:可用在类与方法上,表示参考的类或方法。
/**
* @see java.net.URLDecoder#decode(String, String)
*/
public static String uriDecode(String source, Charset charset){}
以上是方法上常用的文档标注,方法上的文档格式如下:
- 概要描述:通常用一段话简要的描述该方法的基本内容。
- 详细描述:通常用几大段话详细描述该方法的功能与相关情况。
- 文档标注:用于标注该方法的参数、返回值、异常、参略等信息。
以下是String类中charAt方法的示例:
/**
* Returns the {@code char} value at the
* specified index. An index ranges from {@code 0} to
* {@code length() - 1}. The first {@code char} value of the sequence
* is at index {@code 0}, the next at index {@code 1},
* and so on, as for array indexing.
*
* <p>If the {@code char} value specified by the index is a
* <a href="Character.html#unicode">surrogate</a>, the surrogate
* value is returned.
*
* @param index the index of the {@code char} value.
* @return the {@code char} value at the specified index of this string.
* The first {@code char} value is at index {@code 0}.
* @exception IndexOutOfBoundsException if the {@code index}
* argument is negative or not less than the length of this
* string.
*/
public char charAt(int index) {}
(4)变量和常量上的文档规范
变量和常量上用的比较多的文档标记是@link和@code,主要注释该常量或变量的基本用法和相关内容。
以下是示例:
/**
* The value is used for character storage.
*
* @implNote This field is trusted by the VM, and is a subject to
* constant folding if String instance is constant. Overwriting this
* field after construction will cause problems.
*
* Additionally, it is marked with {@link Stable} to trust the contents
* of the array. No other facility in JDK provides this functionality (yet).
* {@link Stable} is safe here, because value is never null.
*/
private final byte[] value;

2、生成帮助文档
首先先展示下我写的文档注释代码:
HelloWorld.java
package demo2;
/**
* <p>这是一个测试javadoc的类
*
* @author codepeace
* @version 1.0
* @since 1.8
*
*/
public class HelloWorld {
String name;
/**
*
* @param name
* @return name
* @throws Exception
* {@code name}
*/
public String test(String name)throws Exception{
return name;
}
}
Doc.java
package demo2;
/**
* <p>这是一个测试javadoc的类
*
* @author codepeace
* @version 1.0
* @since 1.8
*
*/
public class Doc {
String name;
/**
*
* @param name
* @return name
* @throws Exception
* {@code name}
*/
public String test(String name)throws Exception{
return name;
}
}
(1)使用命令行的方式
- 用wiodow打开cmd终端,然后进入要编译的java文件目录的路径中,如下所示:

- 输入命令:
javadoc -encoding UTF-8 -charset UTF-8 \*.java,就能将你的java文件编译成帮助文档。
-encoding 是编码格式, -charset是字符集格式,需要查看你文件的编码格式,可以通过打开记事本查看编码格式。


- 编译成功后你后发现当前路径下会多出很多文件,我们需要的文件是index.html文件。
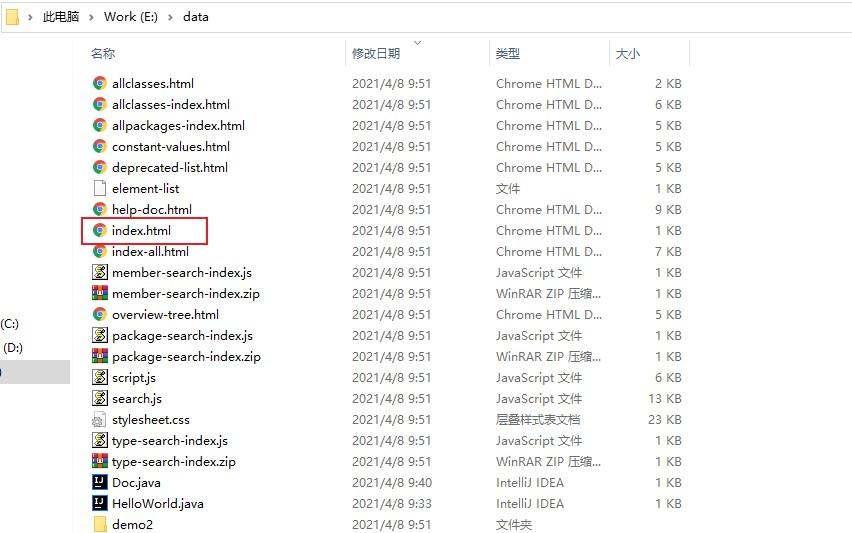
- 点开后为如下样式,至此帮助文档生成完毕。

(2)使用IDE工具的方式
- 打开 idea,点击 Tools-> Generate JavaDoc,这样会打开生成 javadoc 文档的配置页面。

- 配置javadoc文档输出详情:
- 选择要输出文档的范围,选择是整个项目还是模块还是单个文件。
- 文档要输出路径。
- 选择哪些类型的方法或参数可以生成文档。
- Locale 选择地区,这个决定了文档的语言,中文就是zh_CN。
- 传入JavaDoc的参数,一般写
-encoding UTF-8 -charset UTF-8,表示编码格式。

- 点击确定,运行无误后,打开你所选择的文档输出路径后,选择index.html,就是所输出的javadoc文档。


- 打开eclipse,点击 Project-> Generate JavaDoc,这样会打开生成 javadoc 文档的配置页面。

- 配置以下javadoc文档输出详情,后点击next
- 选择要输出成文档的文件或模块
- 选择哪些类型的方法或参数可以生成文档
- 文档要输出路径。

- 设置文档名后,点击next

- 设置编码格式 一般写
-encoding UTF-8 -charset UTF-8,设置jre版本,然后点击完成,在刚才设置的输出路径中找到index.html即可。

-
注意点:eclipse的默认编码不是UTF-8,所以要将其修改为UTF-8,修改方法如下:
打开eclipse,点击 Window-> Preferences->Workspace,将默认的GBK编码改为UTF-8即可。






更多精彩内容敬请关注微信公众号:【平兄聊Java】
bk






