在使用sklean处理一个机器学习实例时,可能会经过数据缩放、特征合并以及模型学习拟合等过程;并且,当问题更为复杂时,所应用到的算法以及模型则较为繁杂。
与此同时,经过实践发现,在忽略一些细节的前提下,可以通过将这些数据处理步骤结合成一条算法链,以更加高效地完成整个机器学习流程;由此,管道(pipeline)概念与机制应运而生。
pipeline概念
所谓管道,即由一系列数据转换步骤或待拟合模型(如果有,则模型必须处于管道末端)构成的加工链条。
下面以实例释之:
未使用管道(pipeline)前

从上图小实例中可以看出,程序中着重有两个数据处理流程,一个是数据缩放MinMaxScaler(),另一个是模型拟合svm.fit(X_train_scaled, y_train),并且两个步骤具有明显的先后顺序,还是分开操作。
使用管道(pipeline)后
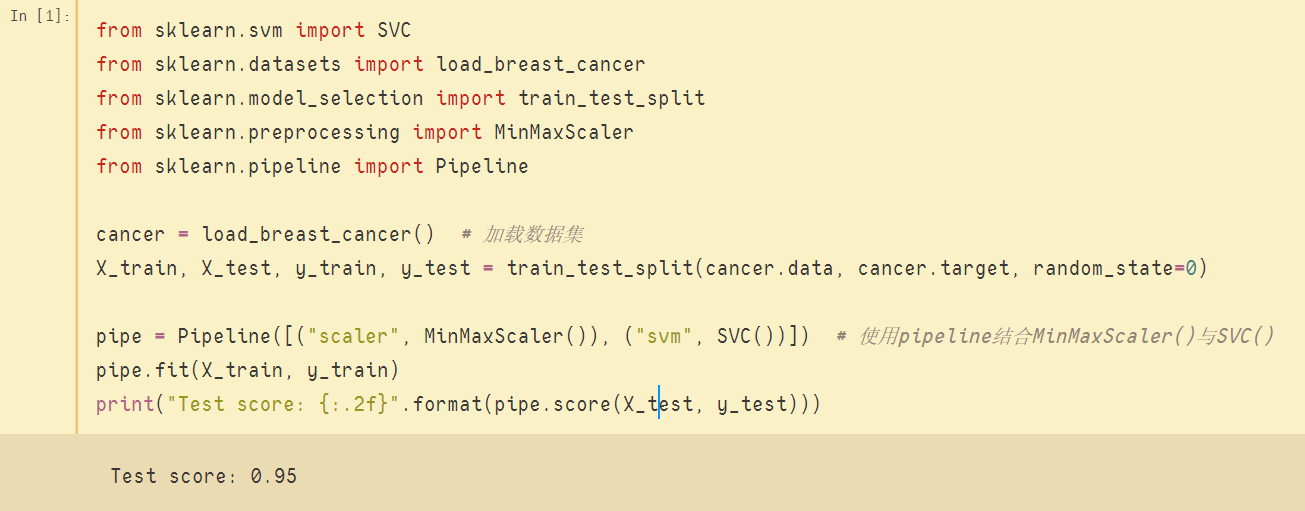
从上图中可以看出,程序将之前的两个步骤结合到一个管道(pipe)中,此后只需将训练数据与测试数据流经管道,则相应的数据转换和模型拟合与应用流程会更加高效且简洁地完成。
为什么使用管道
可能有同学指出,管道只是能简化代码,但也不是缺其不可。实际上,管道的作用不仅在于简化代码,更在于一些关键的数据转换步骤需要管道机制加持,比如交叉验证。
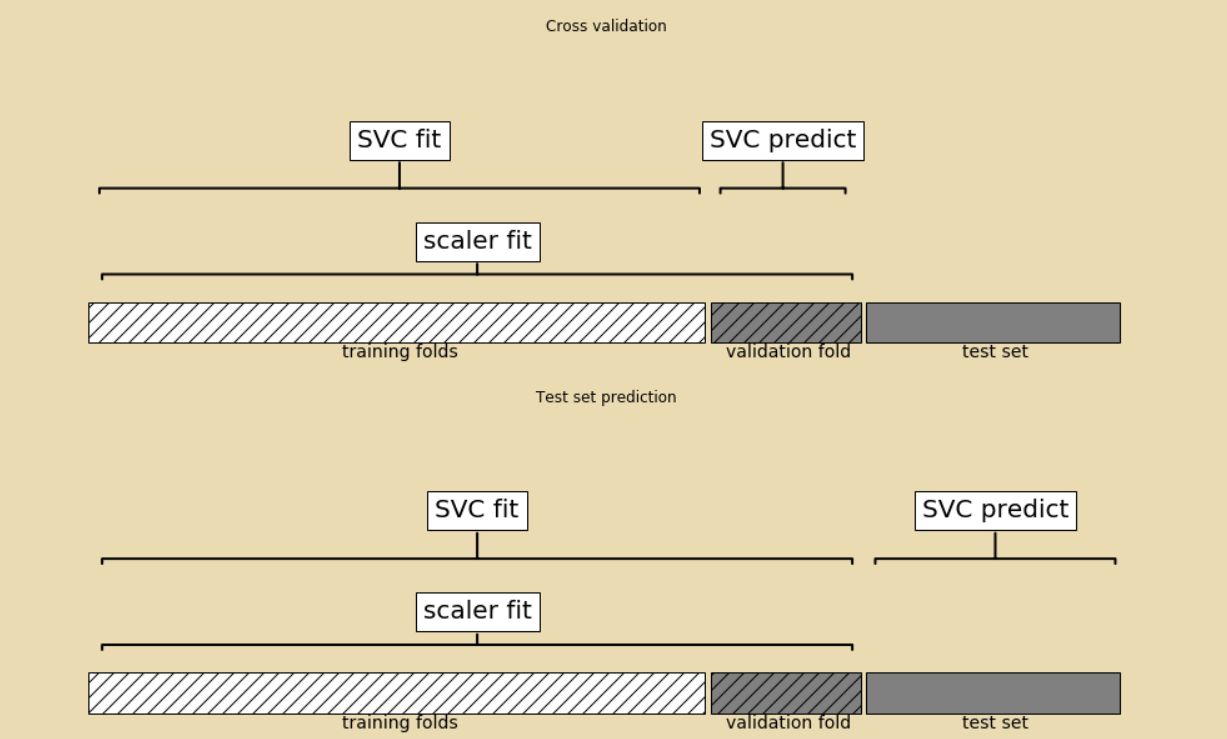
看下图,是使用传统处理流程进行交叉验证的图示;
可以看到,在图的上半部分表示交叉验证区域中,进行数据缩放处理时,同时用到了训练数据与验证数据,但是这是不符合要求的;
即使是验证数据的缩放,也要使用经训练数据拟合过后的MinMaxScaler(),而验证数据本身不应该参与到MinMaxScaler()拟合中,这样会泄露验证数据包含的信息,从而导致验证结果偏离实际。
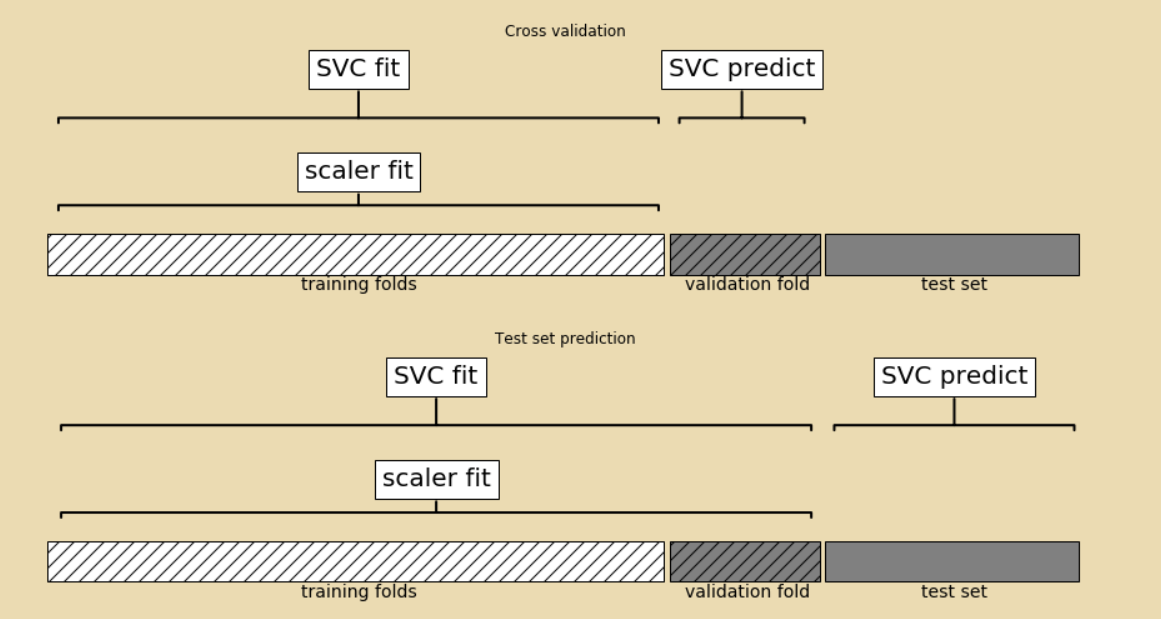
所以,符合要求的交叉验证图示应类似于下图
如果要手动实现上述划分是异常麻烦的,因为需要人工干预每一次的交叉验证操作;但如果用到pipeline,则实现的代码非常简洁,只不过把网格搜索的估计器置换成构建的管道(pipe),部分关键代码如下图:
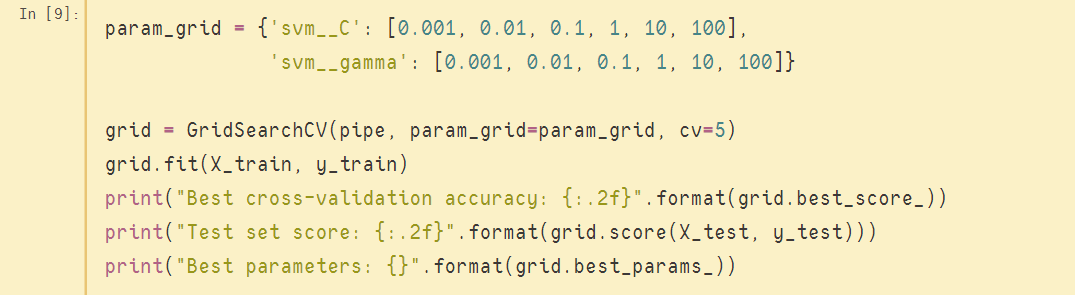
可以看到,在pipeline的加持下,机器学习的步骤更加清晰明了,并且所实现的功能越来越多。
bk