本书部分摘自《Java 并发编程的艺术》
线程通信与同步
在并发编程中,有两个需要处理的关键问题:
通信指线程之间以何种机制来交换信息,通信机制有两种:
- 共享内存:通过读 - 写内存中的公共状态进行隐式通信
- 消息传递:线程之间没有公共状态,线程之间必须通过发送消息来显式进行通信
同步是指程序中用于控制不同线程间操作发生的相对顺序的机制。在共享内存并发模型中,同步是显式进行的,程序员必须显式指定某个方法或某段代码需要在线程之间互斥执行。在消息传递的并发模型里,由于消息的发送必须在消息的接收之前,因此同步是隐式的
Java 内存模型
前面提到线程的通信与同步问题,Java 线程之间的通信由 Java 内存模型(简称 JMM)控制,JMM 决定一个线程对共享变量的写入何时对另一个线程可见
线程之间的共享变量存储在主内存,每个线程都一个私有的本地内存,本地内存中存储了该线程以 读/写 共享变量的副本
Java 内存模型的抽象示意如图
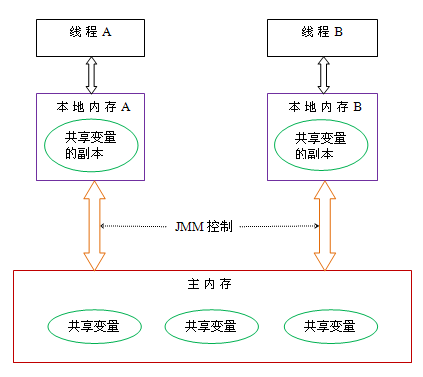
如果线程 A 和线程 B 之间要通信的话,必须经过下面两个步骤:
- 线程 A 把本地内存 A 中更新过的共享变量刷新到主内存中
- 线程 B 到主内存中去读取线程 A 之前已更新的共享变量

这两个步骤实际上是线程 A 向线程 B 发送消息,而且这个通信过程必须经过主内存。JMM 通过控制主内存与每个线程的本地内存之间的交互,来为 Java 程序员提供内存可见性保证
重排序
在执行程序时,为了提高性能,编译器和处理器常常会对指令做重排序。重排序可能会导致线程程序出现内存可见性问题,下面分别介绍三种类型的重排序以及它们对内存可见性的影响:
-
编译器优化的重排序
编译器在不改变单线程程序语义的前提下,可以重新安排语句的执行顺序
-
指令级并行的重排序
现代处理器采用了指令级并行技术来将多条指令重叠执行,如果不存在数据依赖性,处理器可以改变语句对应机器指令的执行顺序
-
内存系统的重排序
由于处理器使用缓存和 读/写 缓冲区,这使得加载和存储操作看上去可能是在乱序执行
这里对第三种情况做个详细解释,现代处理器使用缓冲区临时保存向内存写入的数据,此举可以保证指令流水线持续进行,避免由于处理器停顿下来等待向内存写入数据而产生延迟。但每个处理器上的写缓冲区,仅仅对它所在的处理器可见,这个特性可能会导致处理器对内存的 读/写 操作执行顺序不一定与内存实际发生的 读/写 操作顺序一致。为了说明情况,请看下表:
|
Processor A |
Processor B |
| 代码 |
a = 1; // A1
x = b; // A2 |
b = 2; // B1
y = a; // B2 |
处理器 A 和处理器 B 按程序的顺序并行执行内存访问,最终可能得到 x = y = 0 的结果,具体原因如图
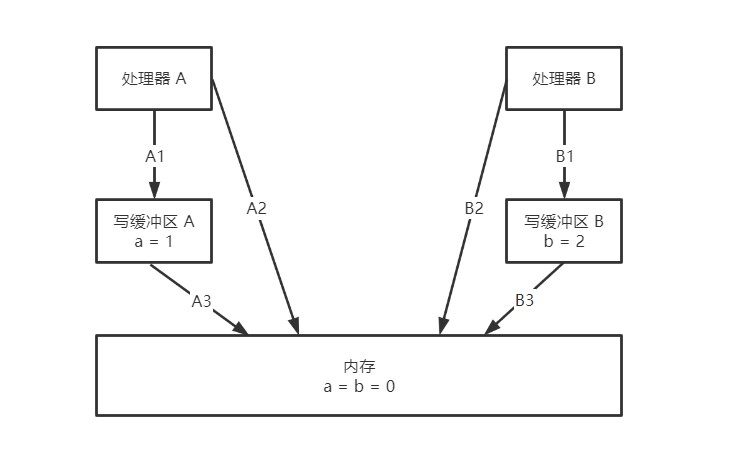
处理器 A 和 处理器 B 同时把共享变量写入自己的缓冲区(A1、B1),然后从内存中读取另一个共享变量(A2、B2),最后才把缓存区中保存的脏数据刷新到内存中(A3、B3),这种情况下,程序最后就得到 x = y = 0 的结果
所以 Java 源代码到最终实际执行的指令序列,会分别经历以下三种重排序

JMM 保证内存可见性
由此可见,JMM 不能任由重排序发生,必须加以控制,否则会引发线程不安全问题。为了更好地解释 JMM 为保证内存可见性所采取的措施,首先介绍一些基础概念
1. 数据依赖性
如果两个操作访问同一个变量,且这两个操作有一个为写操作,此时这两个操作之间就存在数据依赖性,只要重排序这两个操作的执行顺序,程序的执行结果就会被改变。编译器和处理器在重排序时,会遵守数据依赖性,不会改变存在数据依赖关系的两个操作的执行顺序。数据依赖分为下列三种类型:
| 名称 |
代码示例 |
说明 |
| 写后读 |
a = 1;
b = a; |
写一个变量之后,再读这个位置 |
| 写后写 |
a = 1;
a = 2; |
写一个变量之后,再写这个变量 |
| 读后写 |
a = b;
b = 1; |
读一个变量之后,再写这个变量 |
上面三种情况,只要重排序两个操作的执行顺序,程序的执行结果就会被改变
这里所说的数据依赖性仅针对单个处理器中执行的指令序列和单个线程中执行的操作,不同处理器之间和不同线程之间的数据依赖性不被编译器和处理器考虑
2. as-if-serial 语义
as-if-serial 语义的意思是:不管怎么重排序,(单线程)程序的执行结果不能被改变。编译器、runtime 和处理器都必须遵守 as-if-serial 语义,为了遵守 as-if-serial 语义,编译器和处理器不会对存在数据依赖性关系的操作做重排序
as-if-serial 语义把单线程程序保护起来,给程序员创建了一个幻觉:单线程程序是按程序的顺序来执行的,程序员无需担心重排序会干扰他们,也无需担心内存可见性问题
3. happens-before 原则
happens-before 是 JMM 最核心的概念,对于 Java 程序员来说,理解 happens-before 是理解 JMM 的关键。
从 JDK5 开始,Java 使用新的 JSR-133 内存模型,JSR-133 使用 happens-before 的概念来阐述操作之间的内存可见性。在 JMM 中,如果一个操作执行的结果需要对另一个操作可见,那么这两个操作之间必须存在 happens-before 关系,这两个操作既可以是在一个线程之内,也可以是不同线程之间
A happens-before B,就是 A 操作先于 B 操作执行。当然这种说法并不准确,两个操作之间具有 happens-before 关系,仅仅要求前一个操作(执行的结果)对后一个操作可见,且前一个操作按顺序排在第二个操作之前
在 JMM 中定义了 happens-before 的原则如下:
- 单线程 happens-before 原则:在同一个线程中,书写在前面的操作 happens-before 后面的操作
- 锁的 happens-before 原则:同一个锁的 unlock 操作 happens-before 此锁的 lock 操作
- volatile 的 happens-before 原则:对一个 volatile 变量的写操作 happens-before 对此变量的任意操作(当然也包括写操作)
- happens-before 的传递性原则:如果 A 操作 happens-before B 操作,B 操作 happens-before C 操作,那么 A 操作 happens-before C 操作
- 线程启动的 happens-before 原则:同一个线程的 start 方法 happens-before 此线程的其它方法
- 线程中断的 happens-before 原则:对线程 interrupt 方法的调用 happens-before 被中断线程的检测到中断发送的代码
- 线程终结的 happens-before 原则:线程中的所有操作都 happens-before 线程的终止检测
- 对象创建的 happens-before 原则:一个对象的初始化完成先于他的 finalize 方法调用
有关 happens-before 每一个原则的实现,这里不再具体阐述,只要知道有这么一回事就好了
4. 顺序一致性内存模型
顺序一致性内存模型是一个被计算机科学家理想化了的理论参考模型,它为程序员提供了极强的内存可见性保证。顺序一致性内存模型有两大特征:
- 一个线程中的所有操作必须按照程序的顺序来执行
- 不管程序是否同步,所有线程都只能看到一个单一的操作执行顺序。在顺序一致性内存模型中,每个操作都必须原子执行且立刻对所有线程可见
顺序一致性内存模型为程序员提供的视图如下:
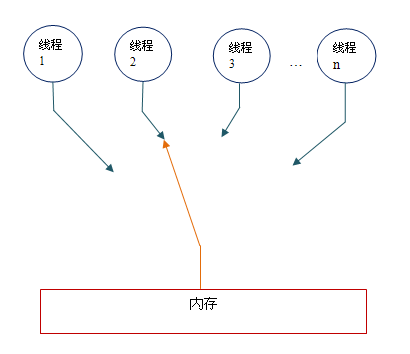
在概念上,顺序一致性模型有一个单一的全局内存,这个内存通过一个左右摆动的开关可以连接到任意一个线程。同时,每一个线程必须按程序的顺序来执行内存读/写操作。从上图我们可以看出,在任意时间点最多只能有一个线程可以连接到内存。当多个线程并发执行时,图中的开关装置能把所有线程的所有内存 读/写 操作串行化
为了更好的理解,下面我们通过两个示意图来对顺序一致性模型的特性做进一步的说明
假设有两个线程 A 和 B 并发执行,其中 A 线程有三个操作,它们在程序中的顺序是:A1 -> A2 -> A3,B 线程也有三个操作,它们在程序中的顺序是:B1 -> B2 -> B3
假设这两个线程使用监视器来正确同步:A 线程的三个操作执行后释放监视器,随后 B 线程获取同一个监视器。那么程序在顺序一致性模型中的执行效果将如下图所示:
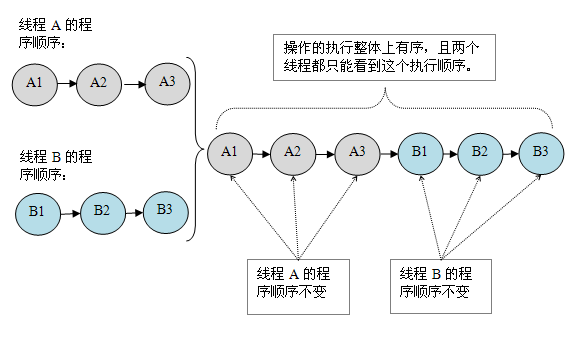
现在再假设这两个线程没有做同步,下面是这个未同步程序在顺序一致性模型中的执行示意图:
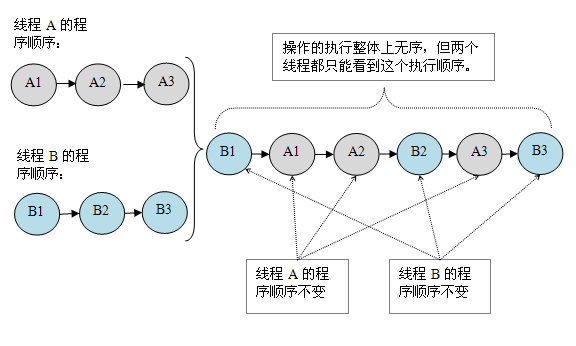
未同步程序在顺序一致性模型中虽然整体执行顺序是无序的,但所有线程都只能看到一个一致的整体执行顺序。以上图为例,线程 A 和 B 看到的执行顺序都是:B1->A1->A2->B2->A3->B3。之所以能得到这个保证是因为顺序一致性内存模型中的每个操作必须立即对任意线程可见
5. 总结
由于重排序的存在,JMM 不可能实现顺序一致性内存模型,同时也不可能完全禁止重排序,因为这样会影响效率。一方面,程序员希望内存模型易于理解、易于编程,希望基于一个强内存模型来编写代码;另一方面,编译器和处理器希望内存模型对它们的束缚越少越好,这样它们就可以做尽可能多的优化来提高性能,编译器和处理器希望实现一个弱内存模型。这两个因素相互矛盾,所以关键在于找到一个平衡点
平衡的关键在于优化重排序规则,根据前面提到的 happens-before 原则、数据依赖性以及 as-if-serial 原则等规定了编译器和处理器什么情况允许重排序,什么情况不允许重排序。对于会改变程序执行结果的重排序,JMM 要求编译器和处理器必须禁止这种重排序,否则不作要求。于是程序员所看到的就是一个保证了内存可见性的可靠的内存模型
下图是 JMM 的设计示意图
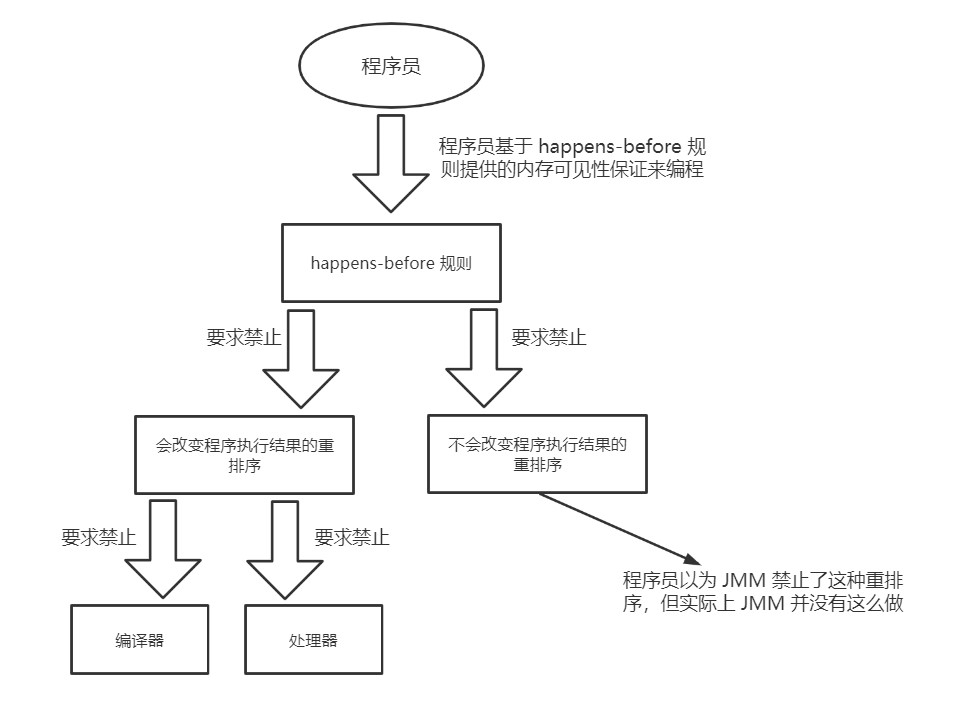
从上图我们也可以发现,JMM 会遵循一个基本原则:只要不改变程序的执行结果(指的是单线程程序和正确同步的多线程程序),编译器和处理器怎么优化都可以。例如,如果编译器经过细致地分析后,认定一个锁只会被单个线程访问,那么这个锁可以被消除。再如,如果编译器经过细致的分析后,认定一个 volatile 变量只会被单个线程访问,那么编译器可以把这个 volatile 变量当作一个普通变量来对待。这些优化既不会改变程序的执行结果,又能提高程序的执行效率。而从程序员的角度来看,程序员其实并不关心重排序是否真的发生,程序员关心的是只程序执行时的语义不能被改变而已