相关性分析
相关性分析解决解决以下两个问题:
- 判断两个或多个变量之间的统计学关联;
- 如果存在关联,进一步分析关联强度和方向
根据变量分布的维度划分,我们有以下两种不同分析角度:
时间维度(一维)
Pearson相关系数
用于度量两个变量X和Y之间的相关程度(线性相关),其值介于-1与1之间,定义为两个变量的协方差除以他们的标准差之积:
\[\rho _{X,Y}=\frac{\mathrm{cov(}X,Y)}{\sigma _X\sigma _Y}=\frac{E\left[ \left( X-\mu _X \right) \left( Y-\mu _Y \right) \right]}{\sigma _X\sigma _Y}
\]
计算公式
\[r=\frac{\sum_{i=1}^{n}\left(X_{i}-\bar{X}\right)\left(Y_{i}-\bar{Y}\right)}{\sqrt{\sum_{i=1}^{n}\left(X_{i}-\bar{X}\right)^{2}} \sqrt{\sum_{i=1}^{n}\left(Y_{i}-\bar{Y}\right)^{2}}}
\]
适用范围:
- 两个变量的标准差都不为零
- 两个变量之间是线性关系,都是连续数据。
- 两个变量的总体是正态分布,或接近正态的单峰分布。
- 两个变量的观测值是成对的,每对观测值之间相互独立。
注意事项:
- 积差相关系数适用于线性相关的情形,对于曲线相关等更为复杂的情形,积差相关系数的大小并不能代表相关性的强弱。
- 样本中存在的极端值对Pearson积差相关系数的影响极大,因此要慎重考虑和处理,必要时可以对其进行剔出,或者加以变量变换,以避免因为一两个数值导致出现错误的结论。
- Pearson积差相关系数要求相应的变量呈双变量正态分布,注意双变量正态分布并非简单的要求x变量和y变量各自服从正态分布,而是要求服从一个联合的双变量正态分布。 (第三条相对比较宽松,违反时系数的结果也是比较稳健的)
结果解释:
·|r|>0.95 存在显著性相关;
·|r|≥0.8 高度相关;
·0.5≤|r|<0.8 中度相关;
·0.3≤|r|<0.5 低度相关;
·|r|<0.3 关系极弱,认为不相关
Spearman秩相关系数
使利用两变量的秩次大小作线性相关分析,对原始变量的分布不做要求,属于非参数统计方法。因此它的适用范围比Pearson相关系数要广的多。即使原始数据是等级资料也可以计算Spearman相关系数。对于服从Pearson相关系数的数据也可以计算Spearman相关系数,但统计效能比Pearson相关系数要低一些(不容易检测出两者事实上存在的相关关系)。如果数据中没有重复值, 并且当两个变量完全单调相关时,斯皮尔曼相关系数则为+1或?1。Spearman相关系数即使出现异常值,由于异常值的秩次通常不会有明显的变化(比如过大或者过小,那要么排第一,要么排最后),所以对Spearman相关性系数的影响也非常小。
其定义为等级变量之间的peason相关系数:
\[\rho=\frac{\sum_{i}\left(x_{i}-\bar{x}\right)\left(y_{i}-\bar{y}\right)}{\sqrt{\sum_{i}\left(x_{i}-\bar{x}\right)^{2} \sum_{i}\left(y_{i}-\bar{y}\right)^{2}}}
\]
其中,其中\(x_{\mathrm{i}},y_{\mathrm{i}}\)为原始变量\(X_{\mathrm{i}},Y_{\mathrm{i}}\)经过等级映射得到,具体映射方式可以取:每个原始数据的降序位置的平均。
记\(d_{i}=x_{i}-y_{i}\),其简化的计算公式为:
\[\rho=1-\frac{6 \sum d_{i}^{2}}{n\left(n^{2}-1\right)}
\]
Kendall's tau-b相关系数
同样是一种秩相关系数,用于反映分类变量相关性的指标,适用于两个变量均为有序分类(有序分类表示类间有强度的逐级递增关系)的情况,用希腊字母τ(tau)表示其值。
基本思想:Kendall系数是基于协同的思想。对于X,Y的两对观察值Xi,Yi和Xj,Yj,如果Xi<Yi并且Xj<Yj,或者Xi>Yi并且Xj>Yj,则称这两对观察值是和谐的,否则就是不和谐。
计算公式
\[\tau=\frac{(\text { number of concordant pairs })-(\text { number of discordant pairs })}{\frac{1}{2} n(n-1)}
\]
例子:
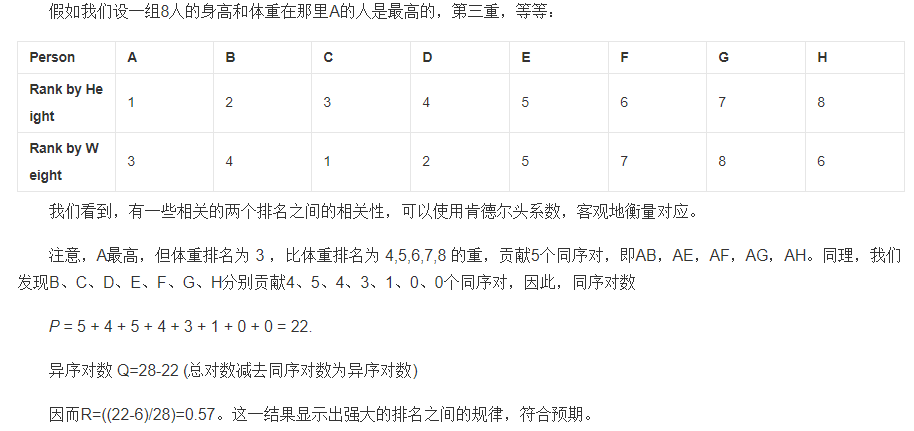
三种系数的关系和区别
- Pearson系数:叫皮尔逊相关系数,也叫线性相关系数,用于进行线性相关分析,是最常用的相关系数,当数据满足正态分布时会使用该系数。两个连续变量间呈线性相关时,使用Pearson积差相关系数。由于其是在原始数据的方差和协方差基础上计算得到,所以对离群值比较敏感。即使pearson相关系数为0,也只能说明变量之间不存在线性相关,但仍有可能存在曲线相关。
- 另外两种统计量:不满足积差相关分析的适用条件时,使用Spearman秩或者kendall相关系数来描述,他们都是更为一般性的非参数方法,对离群值的敏感度较低,因而也更具有耐受性,度量的主要是等级变量之间的联系。
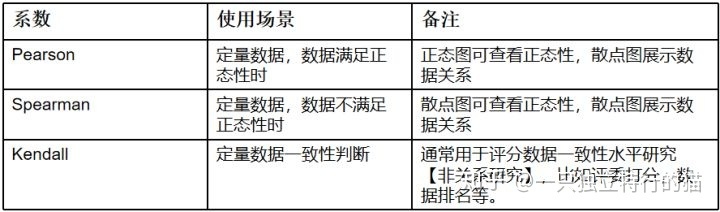
- 最常使用的是Pearson相关系数;当数据不满足正态性时,则使用Spearman相关系数,Kendall相关系数用于判断数据一致性,比如裁判打分。
显著性检测
为了对计算的系数结果做一定的解释,我们可以采用假设检验的方法。
以正相关的检测为例,可以设原假设H0:X和Y相互独立,H1:X和Y正相关;并设\(\alpha\)为显著水平,因此,假设检验的拒绝域分别为:
\[W=\left\{\rho_{s} \geqslant c_{\alpha}\right\}
\]
一种统计量的构造方式

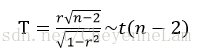
根据计算出的T落在的t分布的位置确定Pvalue后,将其与显著水平对比,如果小于则表示我们以该显著水平拒绝原假设,接受备选假设。
几个常见的显著水平的参数设置:
| P值 |
碰巧的概率 |
对无效假设 |
统计意义 |
| P>0.05 |
碰巧出现的可能性大于5% |
不能否定原假设 |
两组差别无显著意义 |
| P<0.05 |
碰巧出现的可能性小于5% |
可以否定原假设 |
两组差别有显著意义 |
| P <0.01 |
碰巧出现的可能性小于1% |
可以否定原假设 |
两者差别有非常显著意义 |
Python实现
取波士顿房价数据的两个特征:犯罪率和房价数据,我们来验证他们是不是负相关关系
# 复制代码
from pandas import DataFrame
import scipy
import pandas as pd
from sklearn.datasets import load_boston
boston = load_boston()
# print(boston.DESCR)
X = boston.data
Y = boston.target
y = Y[:] # 房价
x = X[:,0] # 城镇人均犯罪率
# data.head()
# data.corr()
data=DataFrame({'x':x,'y':y})
# data.corr(method='pearson')
# data.corr(method='spearman')
# data.corr(method='kendall')
scipy.stats.pearsonr(x, y)
scipy.stats.spearmanr(x, y)
scipy.stats.kendalltau(x, y)
|
r |
p-value |
| pearson |
-0.3883046085868116 |
1.1739870821941207e-19 |
| spearmanr |
-0.5588909488368801 |
6.5533358892281775e-43 |
| kendalltau |
-0.4039635563809384 |
7.87053971116975e-42 |
结果表明,三种方法都显著(以显著水平为1%)地认为两者呈现负相关的关系。
同时,我们希望验证下地区的犯罪率与黑人比例是否有关系:
x = X[:,-3] # 黑人比例
y = X[:,0] # 犯罪比例
data=DataFrame({'x':x,'y':y})
scipy.stats.kendalltau(x, y)
data=DataFrame({'x':x,'y':y})
scipy.stats.pearsonr(x, y)
scipy.stats.spearmanr(x, y)
scipy.stats.kendalltau(x, y)
三个结果表明,两者可以显著地认为呈正相关关系

空间维度(二维)
bk