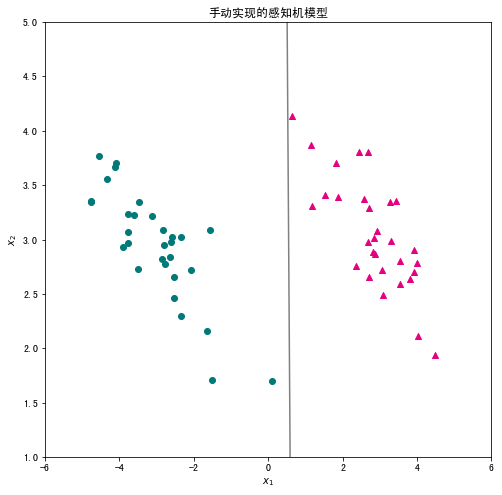
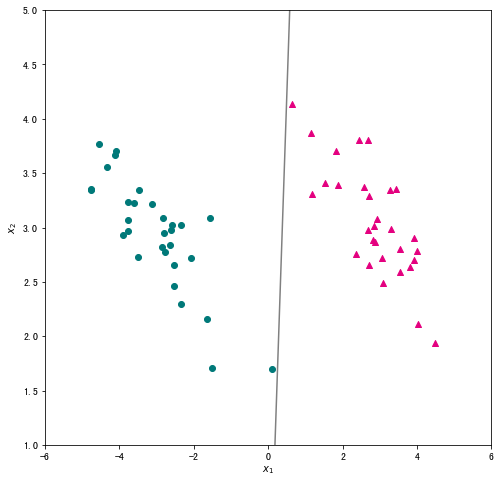
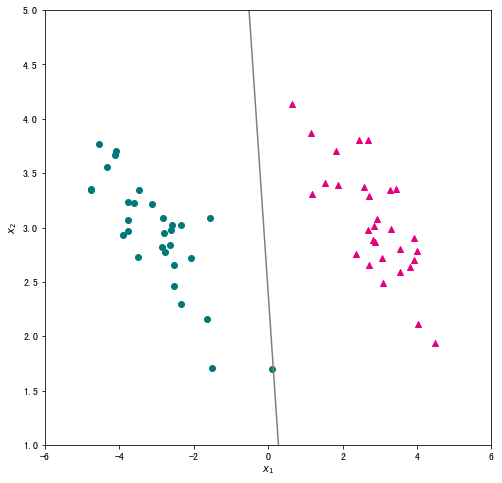
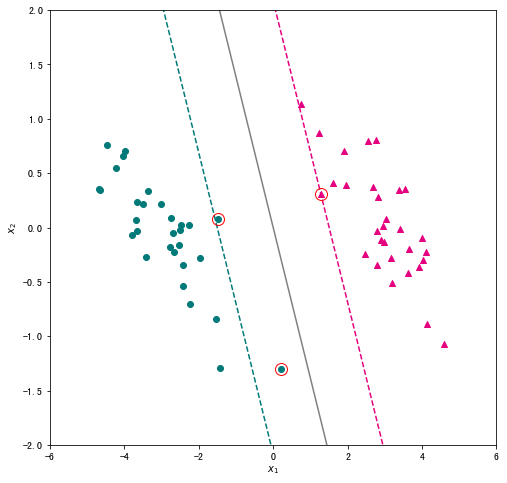
# 创建绘图框
plt.figure(figsize=(8, 8))
# 绘制两类样本点
X_pos = X[ y==1 ]
X_neg = X[ y==-1 ]
plt.scatter(X_pos["x1"],X_pos["x2"],c="#E4007F",marker="^") # 类别为1的数据绘制成洋红色
plt.scatter(X_neg["x1"],X_neg["x2"],c="#007979",marker="o") # 类别为-1的数据绘制成深绿色
# 绘制超平面
x1 = np.linspace(-6, 6, 50)
x2 = - w[0]*x1/w[1]
plt.plot(x1,x2,c="gray")
# 绘制两个间隔超平面
plt.plot(x1,-(w[0]*x1+1)/w[1],"--",c="#007979")
plt.plot(x1,-(w[0]*x1-1)/w[1],"--",c="#E4007F")
# 标注支持向量
for x in support_vectors:
plt.plot(x[0],x[1],"ro", linewidth=2, markersize=12,markerfacecolor='none')
# 添加轴标签和限制轴范围
plt.xlabel("$x_1$")
plt.ylabel("$x_2$")
plt.xlim(-6,6)
plt.ylim(-2,2)