
ǰ��
��һƪ������Ҫ������ν�����ҳ����ƪ������Ҫ��дһ����η��������ܿ���ǰ��ƪ���µ��˾Ϳ�ʼ�ɻ��ˣ������㲻��˵һ�д���Ϳ��Ը㶨��ô����ȷ��һ�д�����ܸ㶨���������ּ�Ȼ������������Ľ�ɫ�������Dz���Ӧ�þ���������ú������һ���������ڵ�һƪ������Ҳ������������ģ���˵���Ϊȥ��ȡ���ݡ���ô���Ǿ���Ҫ֪����һ����ȥ������վ��ʲô������Ϊ��������ôȥģ���˵���Ϊ��
����ͷ
��һ���˴������������ַ���»س����ᷢ��һ��HTTP����Request����������վ����ˣ�����˽�����������Ӧ���ݣ���Response���ڷ�������ʱ��Request����һ������ͷ����Headers��������������Ϣ������Content-type��User-Agent��cookie�ȡ���Ե�Ҳ����һ����Ӧͷ�����ﲻ���ע��
User-Agent
���������Ŀ����У�����ͷ�б������ӵľ���User-Agent��UA��¼�������������ϵͳ���汾����Ϣ���ܶ���վ��ͨ�����UA���ж��Ƿ�����������������
Chrome���������ͷ��Ϣ��
�����������ͷ��Ϣ��
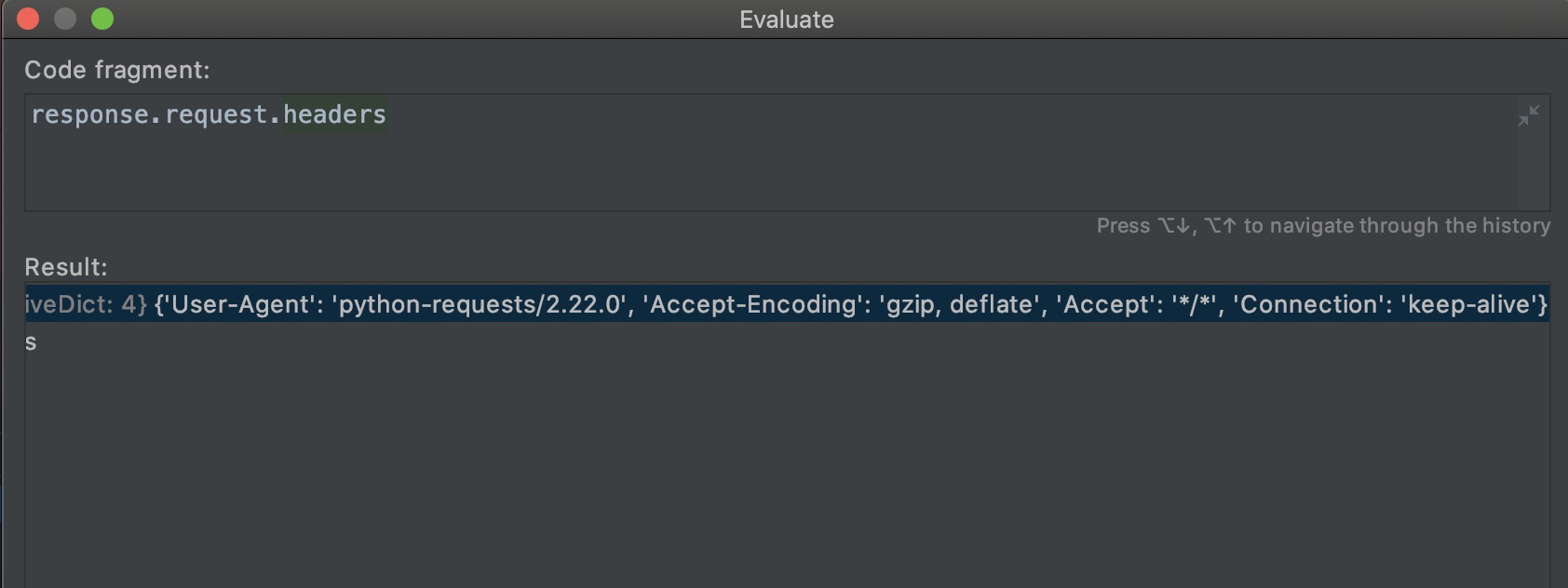
����ͼ���Կ�����Python�����UAĬ�ϵ�python-requests����������Ҫ����������UA��
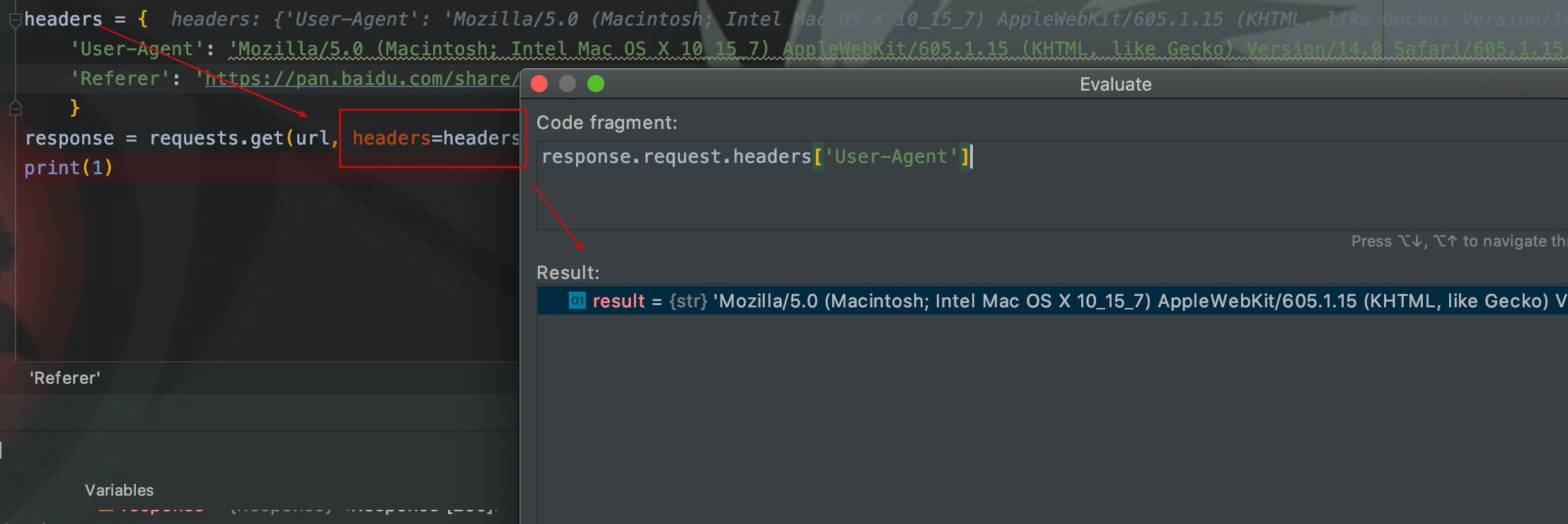
����ͨ��headers����������ͷ����UA������Ĭ�ϵ�UA�ͻᱻ�ġ�
cookie
�����������ԣ��ȽϹ�ע�ľ���cookie����web�����У���������û���һ�η���ʱ����cookie����ͨ����Ӧͷ�е�Set-Cookie���ԣ���������������־û�����cookie����Ч���ڷ��ʷ���ˣ����������������ͷ�д���cookie���Դ��������Լ������ݡ�
�����ٶ�����Ϊ����˵����
��ʱ�һ�û�е�¼�ٶ����̣�ͬʱ����������������й��ڰٶ����̵�cookie����һ�η��ʷ�������ʱ�������ͨ����Ӧͷ�᷵��һ��cookie���������
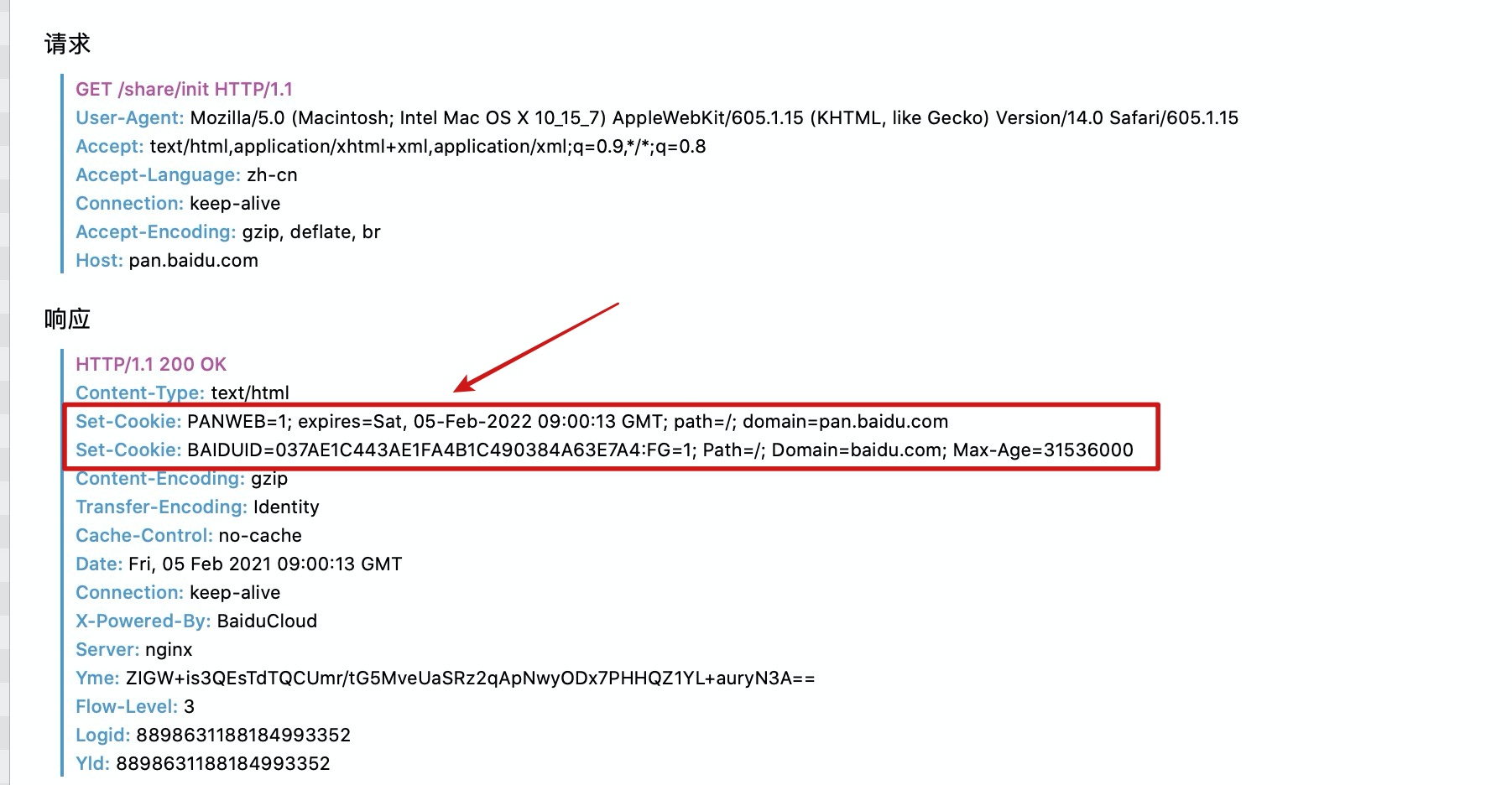
����ˢ��ҳ���ٴ�����ʱ������ͷ�о�����֮ǰcookie���ԡ�
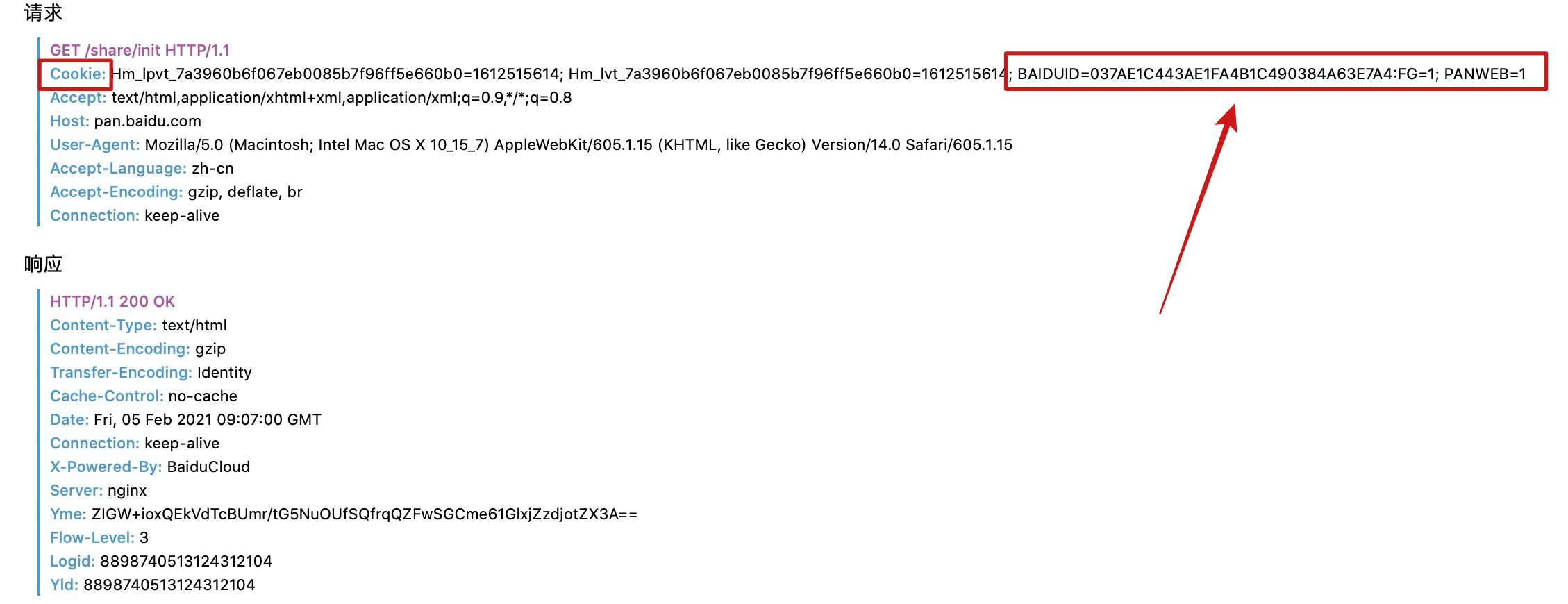
�����cookie����Դ�ͻ����÷���ʵ�ͽ����ˡ�Ϊ�˸��õ�ȥ�ô���˽�һ��cookie�����ֶ�д��һ���֡�
��ʱ�����κ�����ȡ��ķ������ӣ���Ȼ����Ҫ������ȡ�룬��Ϊ����û�е�½�ٶ����̣�Ŀǰ��cookie��������ٶ����̱����ҵ��û���Ϣ�����ǣ���������ڵ�¼�˰ٶ������˺ŵ�������У������Լ��ķ�����������Ҫ������ȡ�룬�����������������
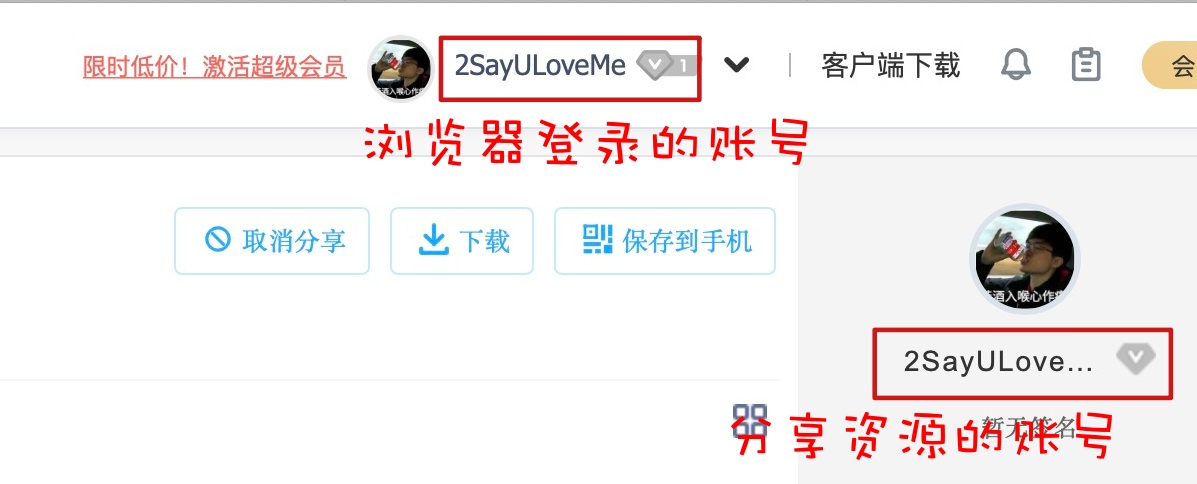
�ٴ�ǿ�����������Լ��˺ŷ�������Դ���Ӳ���Ҫ������ȡ����
�ҵ�¼���Լ��ٶ����̺�ʼ�����Լ��ķ������ӣ�û��������ȡ���ֱ�ӷ��ʵ�����Դ������Ϊɶ�������cookie������������
��¼�ٶ����̣�

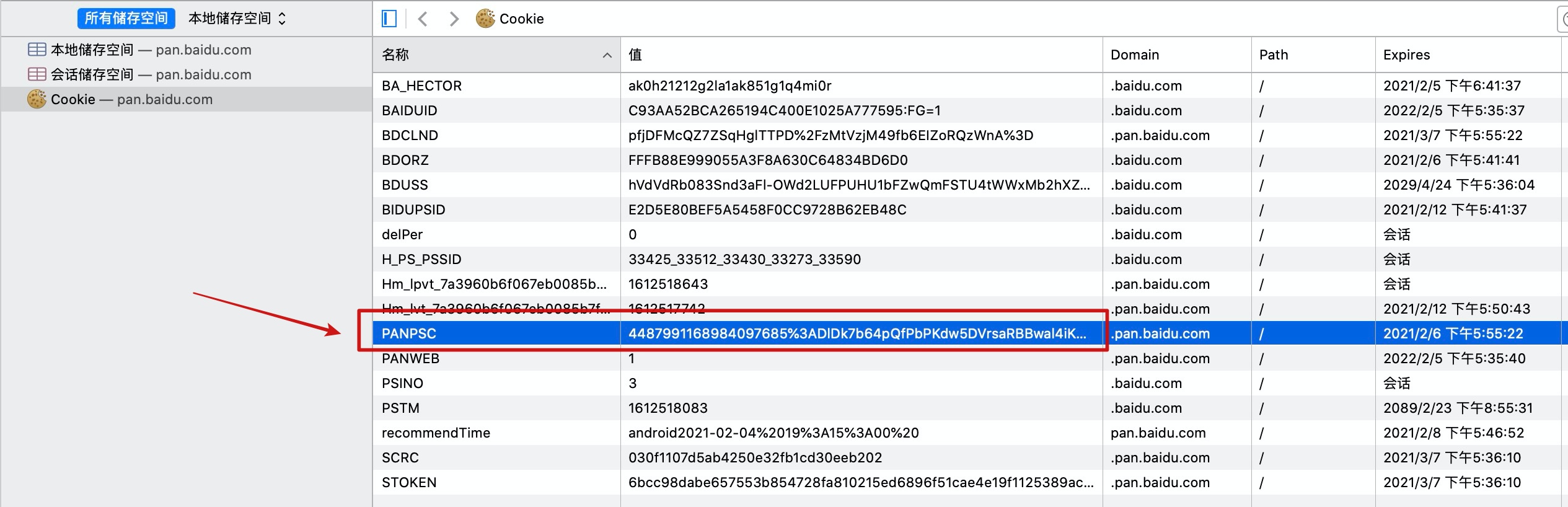
�������ǵ�һ�ε�¼�ٶ����̣��ٶ�����������cookie���ظ����������������ֻ��עPANPAS����ֶεı仯��
���ǿ�һ�´˿�������洢��cookieֵ��
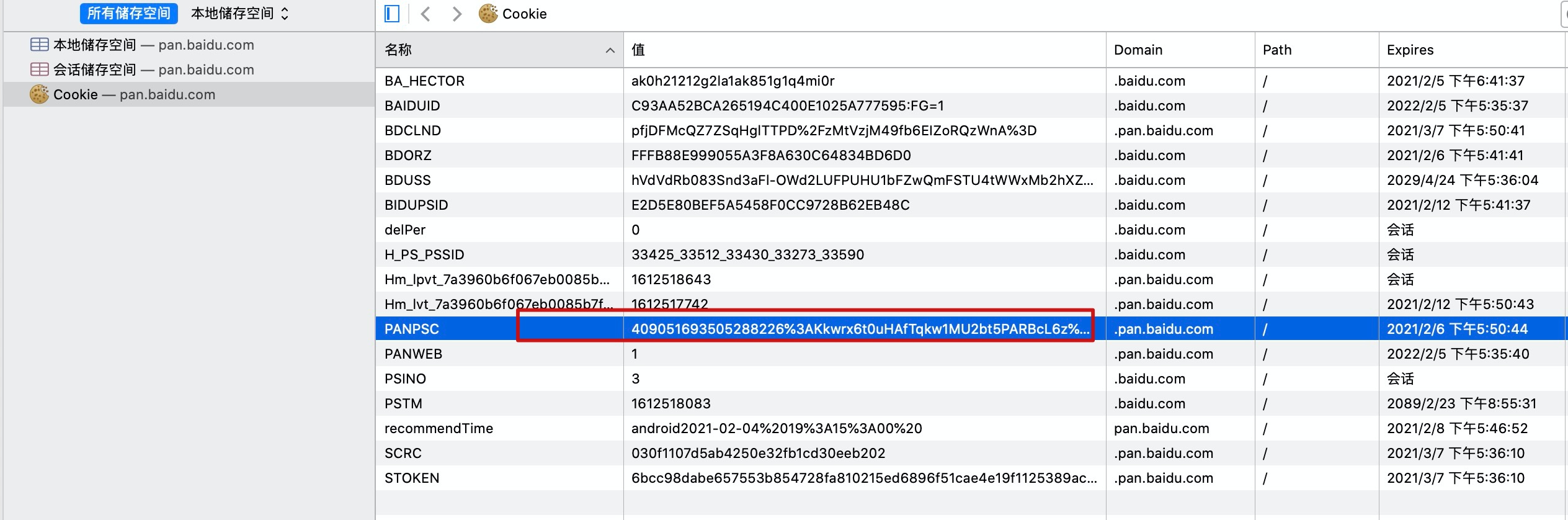
������洢��cookie�͵�һ�ε�¼�ٶ����̷��ص�cookie��һ���ġ�
��ʱ����ˢ��ҳ���ٴη��ʣ�
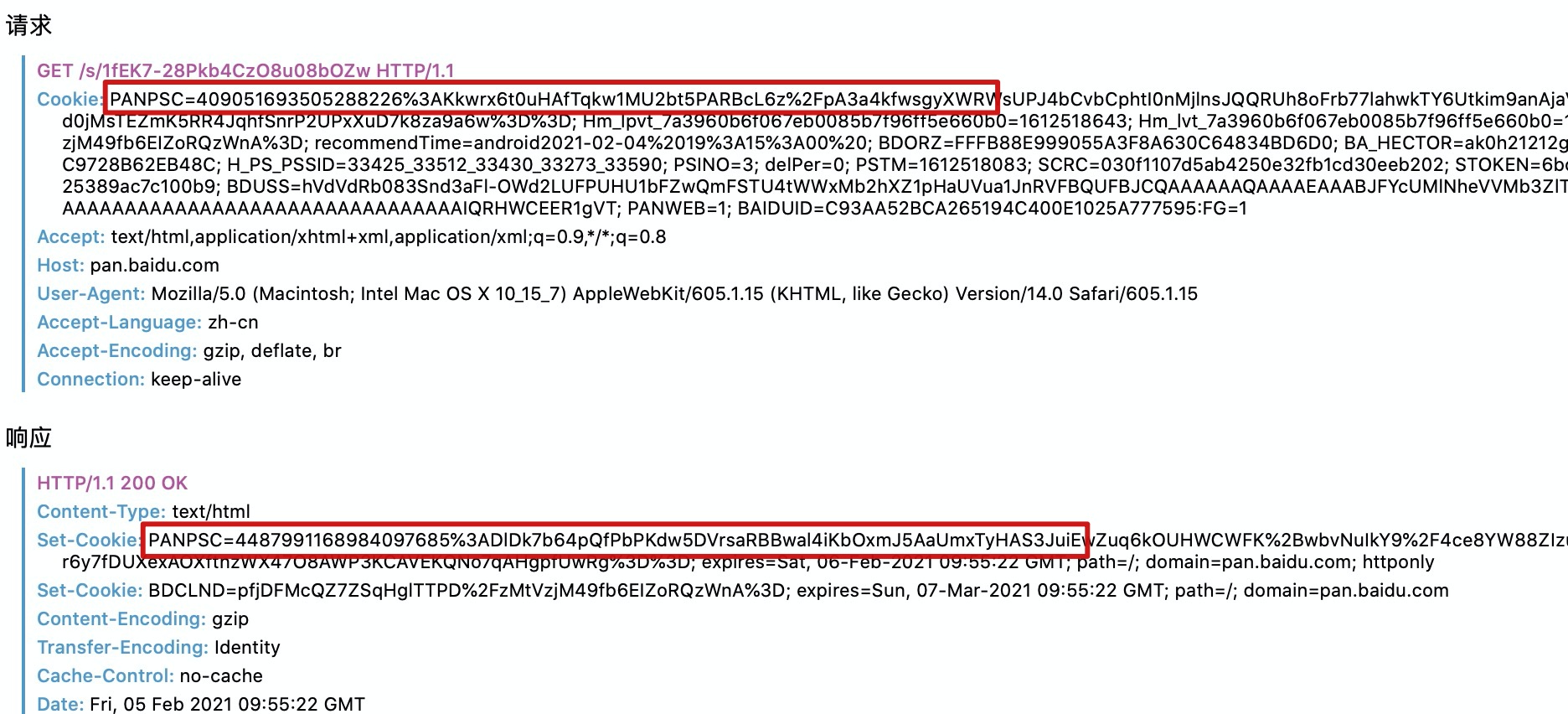
���Ƿ�������ͷ��Я���˸ո�������洢��cookie��������Ӧͷ���ַ�����һ���µ�cookie�������ٿ�һ��������д˿̴洢��cookie��
�˿̣�������д洢��cookie�Ѿ���������µġ���������ܿ���ÿ�η��ʰٶ����̣�����˶����½�һ��cookie���ظ������������֮ǰ��cookie�����Ǵ���վ�������û���һ���������cookie����ʱ�Ż��½�cookie������Ͳ���Ҫ������ᡣ����ֻ��Ҫ֪����cookie�������û���Ϣ���ɡ�
������Ҫ����һЩcookie�ļ����ۣ��������ǴӴ���������cookie���Ӧ�á�
�������Dz���cookie�������ҵİٶ����̷������ӣ�
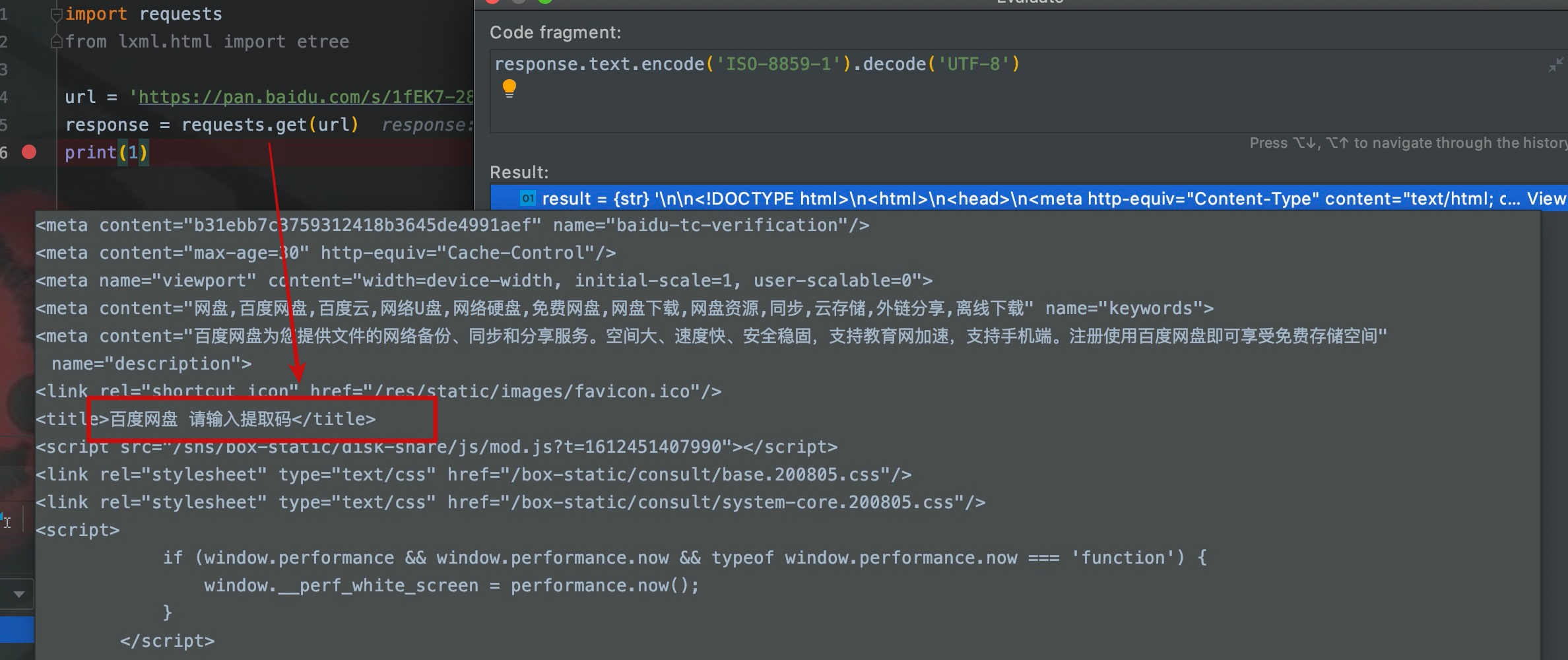
���Ǵ���ҳ���ݿ��Կ������������������ȡ���ҳ�档
��ʱ�����ǽ���¼�˰ٶ����̵�������е�cookie���ƹ�������������ͷ���ٴ�ִ�С�
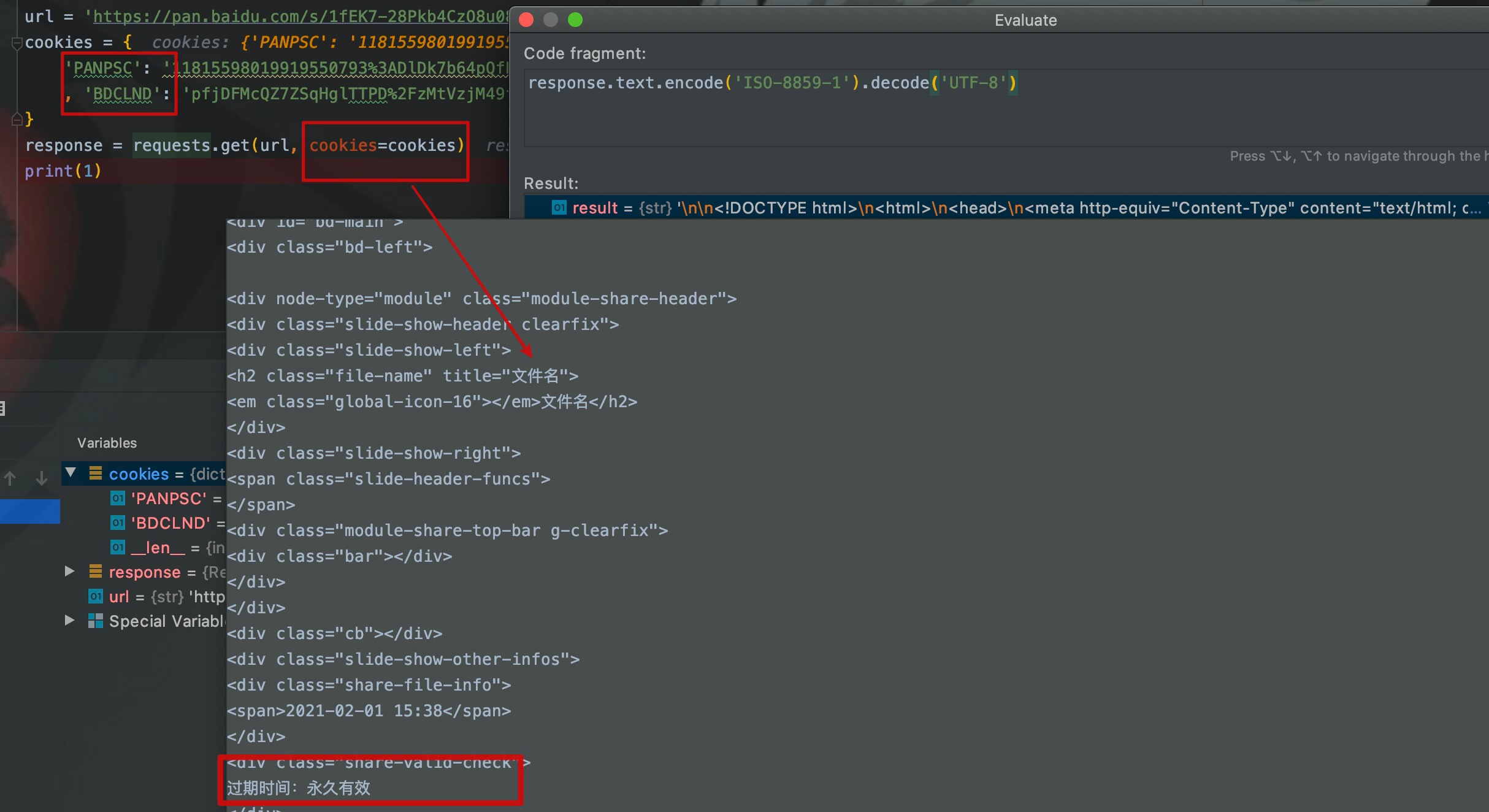
��ͼ������ͷ��Я����cookie֮��������Լ��ķ������ӣ���ֱ�ӷ��ʵ�����Դҳ�棬��������������ȡ��ҳ�档
�����������һ�£�����������cookieȥ���ʷ������ӣ��ٶ�����һ�����cookie�������˺���Դ�����˾�Ȼ��ͬһ���ˣ��ǾͲ���Ҫ���ض���������ȡ��ҳ���ˣ�ֱ�ӷ�����Դ�Ϳ����ˡ�
referer
referer�������Ǵ��ĸ�url��ת����ҳ��ģ�ͨ�������жϴ˴������Ƿ��Ǵ���վ�ڵ�������ġ������Ҵ���Ѷ��Ƶ�Ķ���Ƶ�����ȥ����½����ҳ������ת������½ҳ�������referer���Ƕ���Ƶ����url��
��ͼ��/channle/cartoon�����ľ��Ƕ���Ƶ����

�������ƽʱ����ô�á���ĿǰΪֹ���Ҿ�ֻ��һ����������У�������������⣬��վͨ�����referer���ж����Ƿ���ֱ�ӷ��ʵ����url�������Ҿͽ���վ��ҳ��url���ÿ������ͷreferer�С�
�÷����Կ�UA�Ǹ������ͼ��
����Ƶ��
������֪������������ٶ��Ƿdz���ġ�����������ȡһ����վ�������վ��1w��ҳ�棬�����ڴ�����ѭ������1w�Σ����������������Ӿ㶨�ˣ���������Ϊһ���˻�����ô�������Ƶ��ô������������Ҫ�����������������ܼ�
Java
Thread.sleep(millis)
Python
time.sleep(secs)
Scrapy������
# settings��0.3����0.3s
DOWNLOAD_DELAY = 0.3
����IP
�ܶ���վʶ���������Ļ����ֶξ���ͨ������Ƶ�����жϣ�����¼һ��IP��һ��ʱ���������˶��ٴΡ���������������㹻�Ĵ���IP���Ϳ����������Ƶ�ʡ�
ͨ����ȡ����IP�ķ����и��ѹ���ʹ���Ѵ���IP��վ��ȡ��֮ǰ�����̴�������ר���ṩ��Ѵ���IP����վ������Ѵ���IP�Ĵ����ͨ�����ߡ��ܶ��˾Ϳ�ʼר����Ƴ�������������IP�أ���ȡ����Ѵ���IP֮��ͨ��������֤����IP�Ĵ���ԡ�������Ҫ��˵���������������������Ӵ���IP��
����������һ������IP���������˴����С�
import requests
url = 'https://ipinfo.io'
proxies = {
'https': 'https://183.220.xxx.xx:80'
}
response = requests.get(url, proxies=proxies)
print(response.text)
��IPʶ����վ����������������
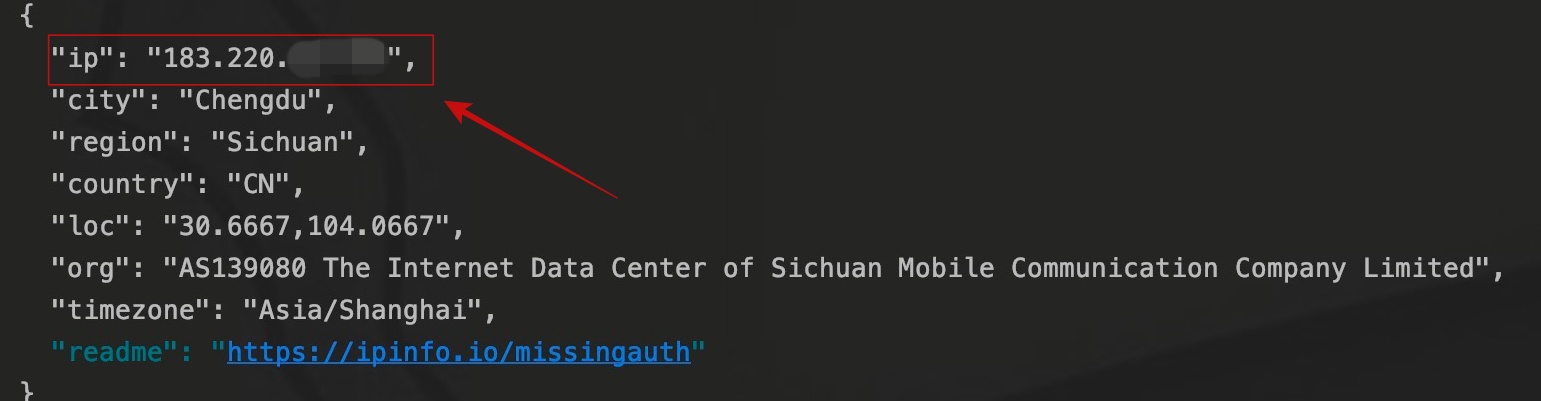
��������IP�Ѿ�������������������IP��������˴���IP�����ڴ����صĹ����������Ժ��һ�дһ�¡�
����
��ƪ���´�����ͷ������Ƶ�ʡ�����IP�������棬�������������ȥģ���˵���Ϊ�������������������ij�ʶ��Ҳ�������Ӧ�Է�����ķ�������ʱ��һ���������ĺû���������ȡ�������������ܣ�����ȡ������վ�Ƿ���ʶ������Ǹ��������
֪������Щ���Ƿ�Ϳ������ɵ���ȥ��ȡ�������أ���ʵ�Dz����Եģ�������ȡ����һ��Ҫ�ں����Ϸ��ķ�Χ�ڣ������Խ���ɵ��ߡ�������ƪ������Ҫ��һ���Լ���������ȡ�淶��һЩ���⡣�ڴ���һ��������
д�Ķ����ճ������е�����ʵ���������Լ��ĽǶȴ�0д��1����֤�ܹ������ô�ҿ�����
���»��ڹ��ں� [���ŵ�����֮·] �����ڴ���Ĺ�ע��

bk