??�ս����˹�����ʵ���ң���֪������ѧϰ����ѧϰ�������ѧϰ����������������һ������������֮���֪����������������Ҳ��Щ���棬�Ͼ���Ҳ�սӴ��������˽⡣
??���һ��Ǹ�����С��֮ʱ��д����ƪ���£�ϣ������ͬ���ڵ���һ�����ո�����������ͬѧ�ܹ����⣬��Խʱ�գ���С����С�Ľ����еõ�Щ��������
# ����һϵ��������ǿ��Ȼ������ѵ����train������֤��val�����Ͳ��ԣ�test�����ݼ�
data_transforms = {
'train': transforms.Compose([
transforms.RandomResizedCrop(input_size),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'val': transforms.Compose([
transforms.Resize(input_size),
transforms.CenterCrop(input_size),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'test': transforms.Compose([
transforms.Resize(input_size),
transforms.CenterCrop(input_size),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
}
����һ���ֵ��������ͣ����м��ֱ�Ϊ��train��val��test��Ӧ���ݼ���������ļ���train��val��test
��train��Ӧ��ֵ��һ������transfroms.Compose( [�б�] )
����Ϊһ���б����б��е�Ԫ��Ϊ�ĸ�������
transforms.RandomResizedCrop()
transforms.RandomHorizontalFlip()
transforms.ToTensor
transforms.ToTensortransforms.Normalize����
transforms��torchvision�У�һ��ͼ������������ͨ��������һЩͼ������������ͼ����д���
transfroms.Compose( [�б�] )���˺���������torchvision.transforms�У�һ����Compose�����Ѷ���������ϵ�һ��
transforms.RandomResizedCrop(����)��������ͼ������ü�Ϊ��ͬ�Ĵ�С�Ϳ��߱ȣ�Ȼ���������ü��õ���ͼ��Ϊ�ƶ��Ĵ�С������������ɼ���Ȼ��Բü��õ���ͼ������Ϊͬһ��С��
���磺
transforms.RandomHorizontalFlip()���Ը����ĸ������ˮƽ��ת������PIL��ͼ��Ĭ��Ϊ0.5��
���磺

transforms.ToTensor��������ͼ��תΪTensor��һ���������ͣ���������ȵľ���
���磺
transforms.ToTensortransforms.Normalize��������һ������
���磺
������ϸ������鿴�˴�����
���Կ�������һ��Ĵ�����Ƕ���һ�ֲ������ϣ���һ��ͼƬ���м��á���ת��תΪһ�����ݡ����ݹ�һ��
�������¿�,��Ӧ�Ľ��Ͷ���ע����
image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x), data_transforms[x]) for x in
['train', 'val', 'test']}
dataloaders_dict = {
x: torch.utils.data.DataLoader(image_datasets[x], batch_size=batch_size, shuffle=True, num_workers=0) for x in
['train', 'val', 'test']}
���������ݵ��벿�֣�������ùٷ�д�õ�torchvision.datasets.ImageFolder�ӿ�ʵ�����ݵ��롣����ӿ���Ҫ���ṩͼ�����ڵ��ļ���
x���ֵ�ļ����Ӻ����for�����ķ�Χ�л�ȡ����'train', 'val', 'test'����ֵ
datasets.ImageFolder(os.path.join(data_dir, x), data_transforms[x])�������������ݼ����ļ���·�����ҵ��ļ���ȷ��x����ִ�еڶ�������data_transforms[x]����x����һЩ�д���
ǰ��torchvision.datasets.ImageFolderֻ�Ƿ����б����б��Dz�����Ϊģ������ģ���Ҳ��֪��Ϊʲô���������PyTorch����Ҫ����һ��������װ�б����Ǿ��ǣ�torch.utils.data.DataLoader
torch.utils.data.DataLoader����Խ��б����͵��������ݷ�װ��Tensor���ݸ�ʽ���Ա�ģ��ʹ�á�
�ã����Ǽ������¿�
# ����һ���鿴ͼƬ�ͱ�ǩ�ĺ���
def imshow(inp, title=None):
# transpose(0,1,2),0��x�ᣬ1��y�ᣬ2��z�ᣬ�ɣ�0��1��2����Ϊ��1��2��0������x��z���Ƚ�����x��y���ٽ���
inp = inp.numpy().transpose((1, 2, 0))
mean = np.array([0.485, 0.456, 0.406]) # ����һ������[0.485, 0.456, 0.406]
std = np.array([0.229, 0.224, 0.225]) # ͬ��Ҳ�Ǵ���һ������
inp = std * inp + mean # ����ͼ��ߴ��С��
inp = np.clip(inp, 0, 1) # С��0�Ķ�Ϊ0������1�Ķ�Ϊ1��֮��IJ���
plt.imshow(inp) # ����ͼ��Ϊ��ɫ
if title is not None: # ���ͼ���б�������ʾ����
plt.title(title) # ����ͼ�����
plt.pause(0.001) # ���ڻ��ƺ�ͣ��0.001��
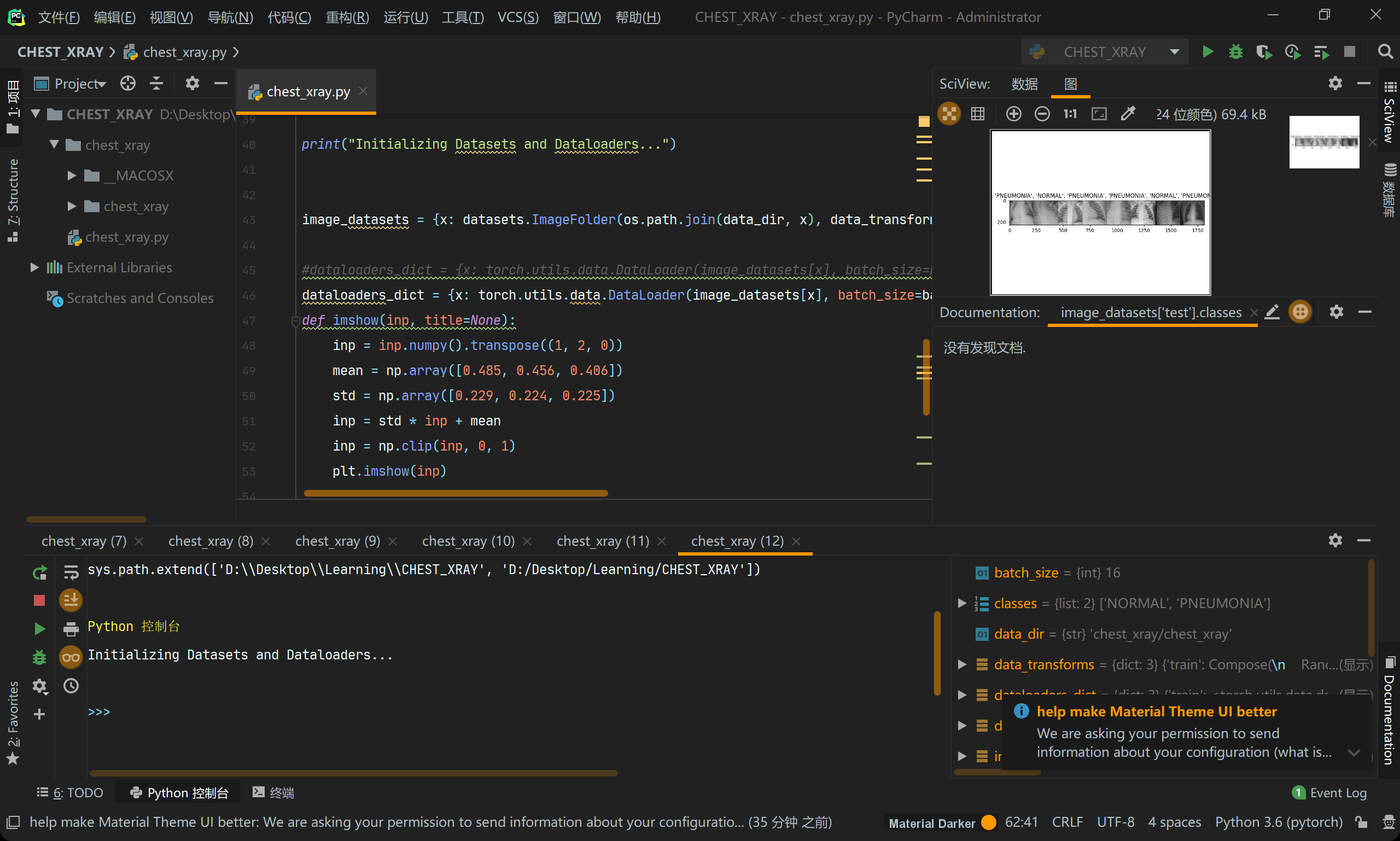
imgs, labels = next(iter(dataloaders_dict['train'])) # �Զ����µ�����������
out = torchvision.utils.make_grid(imgs[:8]) # ��8��ͼƴ��һ��ͼƬ
classes = image_datasets['test'].classes # ÿ��ͼ����ļ���
# out��һ��8��ͼƬƴ�ɵij�ͼ������imshow()�����ӱ���(ͼƬ�ļ�����ǰ8����ĸ)���
# imshow(out, title=[classes[x] for x in labels[:8]])
�������IDE���������ģ����Ͻǣ���
�ã����ڼ���������
�����ظ������ĸ�ѵ��ģ�ͣ�ʵս������ֻ��Ҫ������һ������ѵ���ͺã�������ģ��Ҫע�͵�������������ĸ�ģ���Ҷ������
# inception------------------------------------------------------inceptionģ�ͣ���Ȥ���������Է���Ϊ���οռ�
model = models.inception_v3(pretrained=True)
# inception_v3��һ��Ԥѵ��ģ�ͣ� pretrained=Trueִ�к���ģ�����ص����ǵĵ�����
model.aux_logits = False # �Ƿ��ģ�ʹ���������������ô������̫���ӣ��������ү�����йȸ�
num_fc_in = model.fc.in_features # ��ȡfc��̶��IJ���
# �ı�ȫ���Ӳ㣬2�������⣬out_features = 2
model.fc = nn.Linear(num_fc_in, num_classes) # ��fc�����Ϊnum_classes = 4(��ǰ��ǰ�涨����)
# alexnet--------------------------------------------------------alexnetģ��
model = models.alexnet(pretrained=True) # alexnet��һ��Ԥѵ��ģ�ͣ� pretrained=Trueִ�к���ģ�����ص����ǵĵ�����
num_fc_in = model.classifier[6].in_features # ��ȡfc��̶��IJ���
model.fc = torch.nn.Linear(num_fc_in, num_classes) # ��fc�����Ϊnum_classes = 4(��ǰ��ǰ�涨����)
model.classifier[6] = model.fc
#��ͼ���ʼ��Ϊmodel.fc
#�൱��model.classifier[6] = torch.nn.Linear(num_fc_in, num_classes)
# ����VGG16Ǩ��ѧϰģ��------------------------------------------------vgg16ģ��
model = torchvision.models.vgg16(pretrained=True)# vgg16��һ��Ԥѵ��ģ�ͣ� pretrained=Trueִ�к���ģ�����ص����ǵĵ�����
# �Ƚ�ģ�Ͳ�����Ϊ���ɸ���
for param in model.parameters():
param.requires_grad = False
# �ٸ������һ����������������ֻ�ܸ��ĸò����
model.classifier[6] = nn.Linear(4096, num_classes)
model.classifier = torch.nn.Sequential( # ��ȫ���Ӳ� �Զ��ݶȻ�ָ�ΪĬ��ֵ
torch.nn.Linear(25088, 4096),
torch.nn.ReLU(),
torch.nn.Dropout(p=0.5),
torch.nn.Linear(4096, 4096),
torch.nn.Dropout(p=0.5),
torch.nn.Linear(4096, num_classes))
# resnet18---------------------------------------------------------------resnetģ�ͣ���ǰ����ģ�Ͳ�࣬�Լ��Բ��ɣ�
model = models.resnet18(pretrained=True)
# ȫ���Ӳ������ͨ��in_channels����
num_fc_in = model.fc.in_features
# �ı�ȫ���Ӳ㣬2�������⣬out_features = 2
model.fc = nn.Linear(num_fc_in, num_classes)
����,���Ͷ���ע������
# ����ѵ������
def train_model(model, dataloaders, criterion, optimizer, mundde_epochs=25):
since = time.time() # ���ص�ǰʱ���ʱ�����1970��Ԫ���ĸ���������
# state_dict�������ѵ����������Ҫѧϰ��Ȩ�غ�ƫִϵ����state_dict��Ϊpython���ֵ����ÿһ��IJ���ӳ���tensor������
# ��Ҫע�����torch.nn.Moduleģ���е�state_dictֻ�����������ȫ���Ӳ�IJ���
best_model_wts = copy.deepcopy(model.state_dict()) # copy��һ�����ƺ���
best_acc = 0.0
# ���������������һ�����������������0��9��ʾ����
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('-' * 10)
# ���������������Χ������'train', 'val'����Ӧ��ִ�в�ͬ��ѵ��ģʽ
for phase in ['train', 'val']:
if phase == 'train':
model.train()
else:
model.eval()
running_loss = 0.0
running_corrects = 0.0
for inputs, labels in dataloaders[phase]:
# �������д������˼�ǽ������ʼ��ȡ����ʱ��tensor����copyһ�ݵ�device��ָ����GPU��CPU��ȥ��
# ֮������㶼��GPU��CPU�Ͻ���
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad() # ģ���ݶ���Ϊ0
# ���������е�tensor����������µĽڵ㶼�Dz�����
with torch.set_grad_enabled(phase == 'train'):
outputs = model(inputs) # output���ڰ�inputs�ŵ�ָ���豸��ȥ����
loss = criterion(outputs, labels) # lossΪoutputs��labels�Ľ�������ʧ
# ������output = torch.max(input, dim)
# ����
# input��softmax���������һ��tensor
# dim��max����������ά��0 / 1��0��ÿ�е����ֵ��1��ÿ�е����ֵ
# ���
# �����᷵������tensor����һ��tensor��ÿ�е����ֵ��softmax�������������1�����Ե�һ��tensor��ȫ1��tensor��
# �ڶ���tensor��ÿ�����ֵ��������
_, preds = torch.max(outputs, 1)
if phase == 'train':
loss.backward() # ��������õ�ÿ���������ݶ�ֵ
optimizer.step() # ͨ���ݶ��½�ִ��һ����������
running_loss += loss.item() * inputs.size(0)
running_corrects += (preds == labels).sum().item()
epoch_loss = running_loss / len(dataloaders[phase].dataset)
epoch_acc = running_corrects / len(dataloaders[phase].dataset)
print('{} loss: {:.4f} Acc: {:.4f}'.format(phase, epoch_loss, epoch_acc))
if phase == 'val' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(model.state_dict())
print()
time_elapsed = time.time() - since
print('Training complete in {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60))
print('Best val Acc: {:.4f}'.format(best_acc))
model.load_state_dict(best_model_wts)
return model
�������¿�
# �����Ż�������ʧ����
model = model.to(device) # ǰ�������
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
# optimizer = optim.Adam(model.classifier.parameters(), lr=0.0001)
# sched = optim.lr_scheduler.StepLR(optimizer, step_size=4, gamma=0.1)
criterion = nn.CrossEntropyLoss() # ��������ʧ����
������
class torch.optim.SGD(params, lr=, momentum=0, dampening=0, weight_decay=0, nesterov=False)[source]
ʵ������ݶ��½��㷨��momentum��ѡ����
������
params (iterable) �C ���Ż�������iterable�����Ƕ����˲������dict
lr (float) �C ѧϰ��
momentum (float, ��ѡ) �C �������ӣ�Ĭ�ϣ�0��
weight_decay (float, ��ѡ) �C Ȩ��˥����L2�ͷ�����Ĭ�ϣ�0��
dampening (float, ��ѡ) �C �������������ӣ�Ĭ�ϣ�0��
nesterov (bool, ��ѡ) �C ʹ��Nesterov������Ĭ�ϣ�False��
���ӣ�
optimizer = torch.optim.SGD(model.parameters(), lr=0.1, momentum=0.9)
optimizer.zero_grad()
loss_fn(model(input), target).backward()
optimizer.step()
class torch.optim.Adam(params, lr=0.001, betas=(0.9, 0.999), eps=1e-08, weight_decay=0)
adam�㷨��Դ��Adam: A Method for Stochastic Optimization
Adam(Adaptive Moment Estimation)�������Ǵ��ж������RMSprop���������ݶȵ�һ�ع��ƺͶ��ع��ƶ�̬����ÿ��������ѧϰ�ʡ������ŵ���Ҫ���ھ���ƫ��У����ÿһ�ε���ѧϰ�ʶ��и�ȷ����Χ��ʹ�ò����Ƚ�ƽ�ȡ�
�乫ʽ���£�
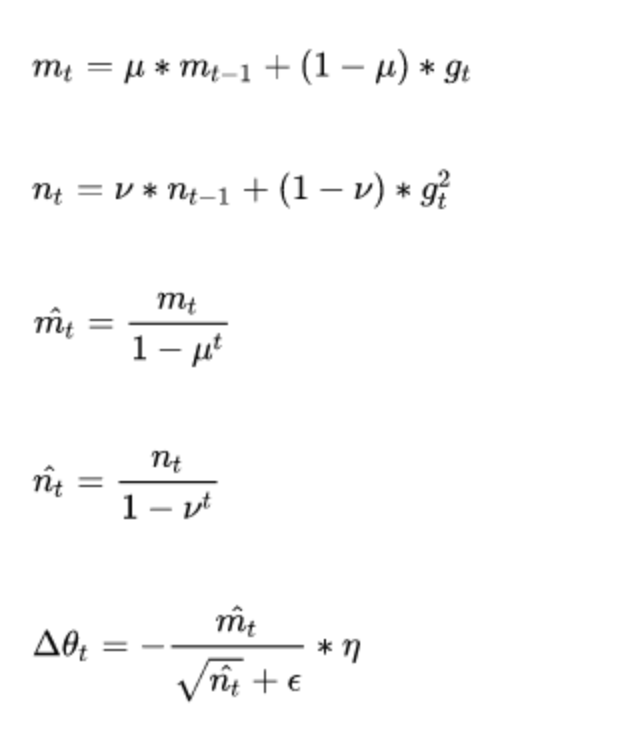
������
params(iterable)�������ڵ����Ż��IJ������߶���������dicts��
lr (float, optional) ��ѧϰ��(Ĭ��: 1e-3)
betas (Tuple[float, float], optional)�����ڼ����ݶȵ�ƽ����ƽ����ϵ��(Ĭ��: (0.9, 0.999))
eps (float, optional)��Ϊ�������ֵ�ȶ��Զ����ӵ���ĸ��һ����(Ĭ��: 1e-8)
weight_decay (float, optional)��Ȩ��˥��(��L2�ͷ�)(Ĭ��: 0)
step(closure=None)������ִ�е�һ���Ż�����
closure (callable, optional)��������������ģ�Ͳ�������ʧ��һ���հ�