Ŀ¼
- 2.1 ���̱߳�̻���
- 2.1.1 ���̸߳���
- 2.1.2 ���̸߳���
- 2.1.3 C++�Ķ��߳�
- 2.1.3.1 C++���̹߳ؼ���
- 2.1.3.2 C++�߳�
- 2.1.3.3 C++���߳�ͬ��
- 2.1.4 ���߳�ʵ�ֻ���
- 2.2 �ִ�ͼ��API�Ķ��߳�����
- 2.2.1 ��ͳͼ��API�Ķ��߳�����
- 2.2.2 DirectX12�Ķ��߳�����
- 2.2.3 Vulkan�Ķ��߳�����
- 2.2.4 Metal�Ķ��߳�����
- 2.3 ��Ϸ����Ķ��߳���Ⱦ
- 2.3.1 Unity
- **2.3.2 Frostbite **
- 2.3.3 Naughty Dog Engine
- 2.3.4 Destiny��s Engine
- 2.4 UE�Ķ��̻߳���
- 2.4.1 UE�Ķ��̻߳���
- 2.4.2 UE�Ķ��߳�ʵ��
- 2.4.2.1 FRunnable
- 2.4.2.2 FRunnableThread
- 2.4.2.3 QueuedWork
- 2.4.2.4 TaskGraph
- 2.5 UE�Ķ��߳���Ⱦ
- 2.5.1 UE�Ķ��߳���Ⱦ����
- 2.5.1.1 ��������Ⱦģ����Ҫ����
- 2.5.1.2 ����ģ�����Ⱦģ�����
- 2.5.1.3 ��Ϸ�̺߳���Ⱦ�̴߳���
- 2.5.2 UE�Ķ��߳���Ⱦ����
- 2.5.3 ��Ϸ�̺߳���Ⱦ�̵߳�ʵ��
- 2.5.3.1 ��Ϸ�̵߳�ʵ��
- 2.5.3.2 ��Ⱦ�̵߳�ʵ��
- 2.5.3.3 RHI�̵߳�ʵ��
- 2.5.4 ��Ϸ�̺߳���Ⱦ�̵߳Ľ���
- 2.5.5 ��Ϸ�̺߳���Ⱦ�̵߳�ͬ��
- 2.6 ���߳���Ⱦ����
- �ر�˵��
- �����
2.1 ���̱߳�̻���
Ϊ�˸�ƽ�ȵع��ɣ�����������UE�Ķ��߳���Ⱦ֪ʶ֮ǰ����ѧϰ������һ�¶��̱߳�̵Ļ���֪ʶ��
2.1.1 ���̸߳���
���̣߳�Multithread����̵�˼�����ڵ���ʱ�����Ѿ������ˣ���ʱ�IJ���ϵͳ����Windows95�����Ѿ�֧�ֶ�����Ĺ��ܣ���ԭ�������ڵ������л���ͬ�������ģ�Context�����Ա�ÿ�������е��̶߳���ʱ����ִ��ָ��Ļ��ᡣ
������2005�꣬��������Ƶ�ӽ�4GHzʱ��CPUӲ������Ӣ�ض���AMD���֣��ٶ�Ҳ�������Լ��ļ��ޣ��Ǿ��ǵ�������Ƶ�������Ѿ�����������ϵͳ�������ܡ�
���ŵ��˼���Ƶ��Ħ�����ɵĻ����սᣬIntel������2005�귢���˱���D�ͱ����������840ϵ�У��״�֧������������������̼߳��㵥Ԫ���˺�ʮ���꣬���CPU�õ����չ����AMD�����Ryzen 3990X�������Ѿ�ӵ��64������128�����̡߳�

������Ryzen��3990X�����������к�Ȼ�Եĺ������߳�������
Ӳ���Ķ�˷�չ������������ķ��ӿռ䡣Ӧ�ó�����Գ�ַ��Ӷ�˶��̵߳ļ�����Դ������Ӧ�������ɴ�Ҳ�������̱߳��ģ�ͺͼ�������Ϊ��Ϸ�ķ�����Unreal Engine����ҵ���棬ͬ���������ö��̼߳������Ա���ӳ�ֵ�����Ч�ʺ�Ч����
ʹ�ö��̲߳��������������ܽ�������Ҫ�����㣺
- �����ע�㡣ͨ������صĴ������صĴ�����룬����ʹ�������������Ͳ��ԣ��Ӷ����ٳ����Ŀ����ԡ����磬��Ϸ������ͨ�����ļ����ء����紫�����������߳��У��ȿ��Բ��谭���̣߳�Ҳ���Է��������룬ʹ�ø�����������չ��
- �������ܡ��˶������������ĵ���ͬ���õ�CPU�ϣ��˶���������ͬ��������������ܹ���ɢ�����CPU��ͬʱ���У���Ȼ�����Ч�ʵ�������
���ǣ�����CPU�����������������������õ�Ч�沢��ֱ��������������ѭAmdahl's law����ķ������ɣ���Amdahl's law�Ĺ�ʽ�������£�
\[S_{latency}(s) = \frac{1}{(1-p) + \frac{p}{s}}
\]
��ʽ�ĸ��������������£�
- \(S_{latency}\)�����������ڶ��̴߳����������ϻ�õļ��ٱȡ�
- \(s\)������ִ�������в��ֵ�Ӳ����Դ���߳�������
- \(p\)���ɲ��д���������ռ�ȡ�
�ٸ���������ӣ�������8��16�̵߳�CPU���ڴ���ij���������������70%�IJ����ǿ��Բ��д����ģ���ô�������ۼ��ٱ�Ϊ��
\[S_{latency}(16) = \frac{1}{(1-0.7) + \frac{0.7}{16}} = 2.9
\]
�ɴ˿ɼ������̱߳�̴�����Ч�沢�Ǹ���������ֱ�����ȣ�ʵ������������������ʾ��
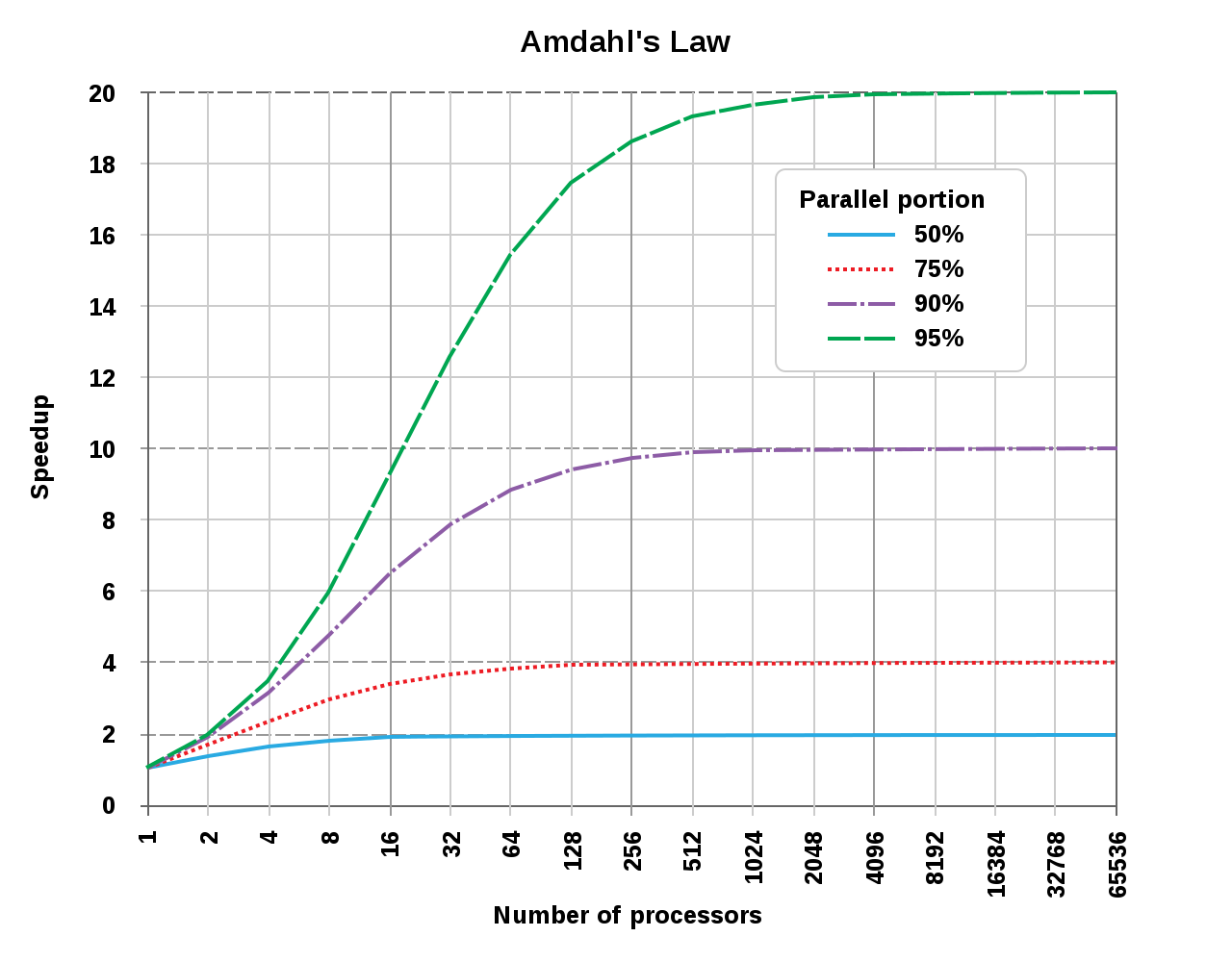
��ķ������ɽ�ʾ�ĺ������ͼ��ٱ�ͼ�����ɴ˿ɼ����ɲ��е�����ռ��Խ�ͣ����ٱȻ�õ�Ч��Խ����ɲ�������ռ��Ϊ50%ʱ��16���Ѿ������ﵽ���ٱ��컨�壬���ۺ������Ӷ��ٺ����������������£�����ɲ�������ռ��Ϊ95%ʱ����2048�����IJŻ�ﵽ���ٱ��컨�塣
��Ȼ��ķ������ɸ����Ǵ����˲п����ʵ�����ǣ���������ܹ�����������ռ�ȵ��ӽ�100%������ٱ��컨����Եõ�����������
\[S_{latency}(s) = \frac{1}{(1-p) + \frac{p}{s}} = \frac{1}{(1-1) + \frac{1}{s}} = s
\]
���Ϲ�ʽ��ʾ����\(p=1\)�����ɲ��е�����ռ��100%��ʱ�������ϵļ��ٱȺͺ����������������ȣ���
�ٸ���������ӣ��ڱ���Unreal Engine����Դ���Shaderʱ���������ǻ�����100%�IJ���ռ�ȣ������Ͽ��Ի�ýӽ����Թ�ϵ�ļ��ٱȣ��ڶ��ϵͳ�н���������̱���ʱ�䡣
���ö��̲߳���������ܵķ�ʽ�����֣�
- �����У�task parallelism������һ����������ֳɼ����֣��Ҹ��Բ������У��Ӷ�����������ʱ�䡣���ַ�ʽ��Ȼ�������ܼ�ֱ�ۣ���ʵ�ʲ����п��ܻ�ܸ��ӣ���Ϊ�ڸ�������֮����ܴ�����������
- ���ݲ��У�data parallelism���������е����㷨��ִ��ָ����֣���ÿ���߳�ִ�е�ָ�һ���������ݲ�����ָ����ͬ����ִ�е����ݲ�һ����SIMDҲ�����ݲ��е�һ�ַ�ʽ��
��������˶��̲߳������洦��������˵˵���ĸ����á��ܽ����������������£�
- �������ݾ��������̷߳��ʳ����ύ��ִ��ͬһ�δ��룬���߲���ͬһ����Դ���ֻ��߶��CPU�ĸ߶Ȼ���ͬ�����⣬�ɴ˱仯�����������ݲ�ͬ�������ݶ�д�����ɴ˲����˸��ָ������쳣�������������ݾ�����
- �����ӻ������Ե��ԡ����ڶ��̵߳IJ�����ʽ��Ψһ������Ԥ֪������Ϊ�˱������ݾ������������븴�Ӷ�����ͬ������������Ҳ������ɢ��Ƭ�λ����������������⣬���Ӵ���ĸ������Ժ�����ά������չ���������ɹ������谭��Ҳ������С�����¼��������ֵ�BUG�������ԺͲ�����������������Ѷȡ�
- ��һ���ܹ�����Ч�档���̼߳����õõ�ȷʵ�����Ч�ʵ������������Ǿ��ԣ������������ġ�ͬ�����ơ�����ʱ״̬������ռ�ȵȵ�������أ���ijЩ��������������õò����������ܷ����ή�ͳ���Ч�ʡ�
2.1.2 ���̸߳���
��С�ڽ��������̱߳�̼����г��漰�Ļ������
���̣�Process���Dz���ϵͳִ��Ӧ�ó���Ļ�����Ԫ��ʵ�壬������ֻ�Ǹ�������ͨ�������ں˶���ַ�ռ䡢ͳ����Ϣ�������̡߳���������������ִ�д���ָ����ǽ��ɽ����ڵ��߳�ִ�С�
��Windows���ԣ�����ϵͳ�ڴ�������ʱ��ͬʱҲ���������һ���̣߳����̱߳���Ϊ���߳���Primary thread, Main thread����
��Unix���ԣ����̺����߳���ʵ��ͬһ������������ϵͳ����֪�����̵߳Ĵ��ڣ��̸߳��ӽ���lightweight processes�����������̣��ĸ��
���������ȼ����Windows���ɵ͵���Ϊ���ͣ�Low��������������Below normal����������Normal��������������Above normal�����ߣ�High����ʵʱ��Real time����������ͼ��
Ĭ������£����̵����ȼ�ΪNormal�����ȼ��ߵĽ��̽������Ȼ��ִ�л����ʱ�䡣
�̣߳�Thread���ǿ���ִ�д����ʵ�壬ͨ�����ܶ������ڣ���Ҫ������ij�������ڲ���һ�����̿���ӵ�ж���̣߳���Щ�߳̿��Թ������̵����ݣ��Ա㲢�л���ִ�ж������
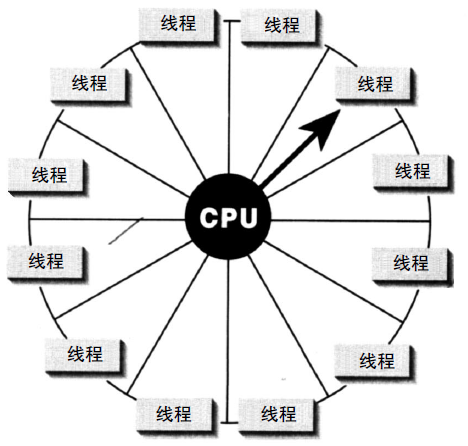
�ڵ���CPU�У�����ϵͳ����Windows�����ܻ������ѭ��Round robin���ķ�ʽ���е��ȣ�ʹ�ö���߳̿�������ͬʱ���еġ�����ͼ��
�ڶ��CPU�У��߳̿��ܻᰲ���ڲ�ͬ��CPU����ͬʱ���У��Ӷ��ﵽ���д�����Ŀ�ġ�
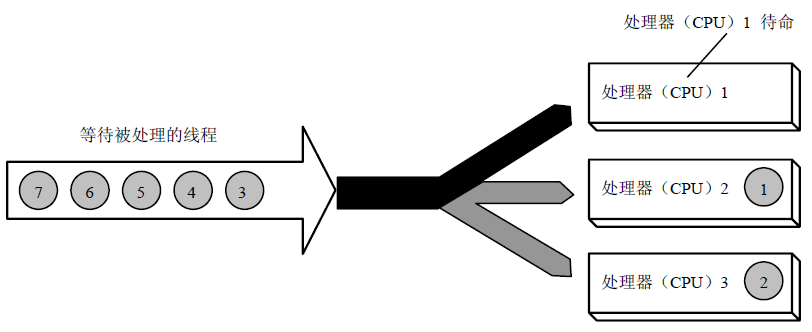
����SMP��Windows�ڶ��CPU��ִ��ʾ��ͼ���ȴ��������̱߳����ŵ���ͬ��CPU���ġ�
ÿ���߳̿�ӵ���Լ���ִ��ָ�������ģ���Windows��IP��ָ��Ĵ�����ַ����SP��ջ��ʼ�Ĵ�����ַ������ִ��ջ��TLS��Thread Local Storage���ֲ߳̾����棩��
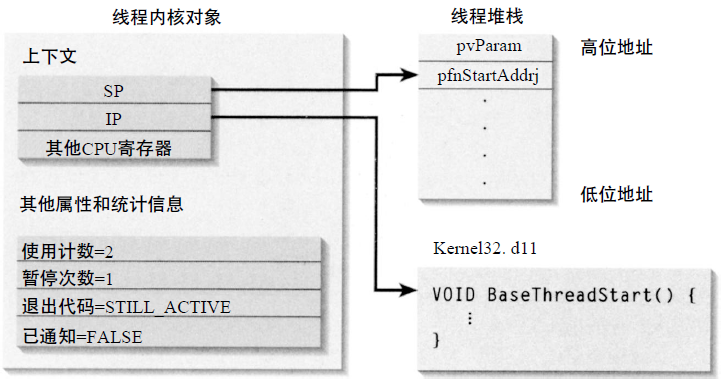
Windows�̴߳����ͳ�ʼ��ʾ��ͼ��
�ֲ߳̾��洢��Thread Local Storage����һ�ִ洢�����ڣ�����������������߳�һ�������߳̿�ʼʱ���䣬�߳̽���ʱ���ա�ÿ���߳��иö����Լ���ʵ�������ʺ��������Ķ�����ɾ���������Race Condition����
�߳�Ҳ�������ȼ�������ȼ�Խ�ߵĽ����Ȼ��ִ��ָ��Ļ��ᡣ
�̵߳�״̬һ��������״̬����ͣ״̬�ȡ�Windows�������½ӿ��л��߳�״̬��
// ��ͣ�߳�
DWORD SuspendThread(HANDLE hThread);
// ���������߳�
DWORD ResumeThread(HANDLE hThread);
ͬ���߳̿ɱ������ͣ�����Ҫ�ָ�����״̬������Ҫ����ͬ�ȴ����ļ������нӿڡ�
Э�̣�Coroutine����һ����������lightweight�����û�̬�̣߳�ͨ������ͬһ���̣߳�����ͬһ���̵߳IJ�ͬʱ��Ƭ��ִ��ָ�û���̡߳������л��͵��ȵĿ�������ʹ���߽Ƕȣ���������Э�̻���ʵ����ͬ���߳�ģ���첽������ͱ��뷽ʽ����ͬ���߳��ڣ�������������ݾ�������Ҳ�����߳�������������
�˳̣�Fiber����ͬЭ�̣�Ҳ��һ�����������û�̬�̣߳�����ʹ��Ӧ�ó�����������Լ����߳�Ҫ�������������ϵͳ�ں˲�֪���˳̵Ĵ��ڣ�Ҳ����Ϊ�����е��ȡ�
- ����������Race Condition��
ͬ�����������ж���̣߳���Щ�߳̿��Թ������̵ĵ�ַ�ռ䡢���ݽṹ�������ġ������ڵ�ͬһ���ݿ飬���ܴ��ڶ���߳���ij����С��ʱ��Ƭ����ͬʱ��д����ͻ���������쳣���Ӷ������˲���Ԥ�ϵĽ�������ֲ���Ԥ���Ա����������������Race Condition����
����������������ļ����кܶ࣬����ԭ�Ӳ������ٽ�������д�����ں˶����ź����������塢դ�������ϡ��¼��ȵȡ�
���������߳�ͬʱִ������Ļ��ơ�һ���ж�˶������̵߳�CPUͬʱִ�е���Ϊ���ſ��Խв��У����˵Ķ��̲߳��ܳ�֮Ϊ���С�
���������߳�����ʱ��Ƭ��Timeslice��ִ������Ļ��ƣ��Dz��еĸ��ձ���ʽ�����㵥��CPUͬʱִ�еĶ��̣߳�Ҳ�ɳ�Ϊ������
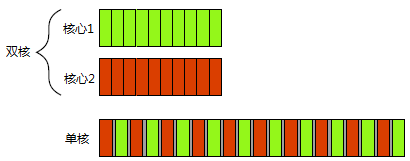
������������ʽ�����ϣ�˫�������ĵ�ͬʱִ�У����У����£����˵Ķ������л�����������
��ʵ�ϣ������Ͳ����ڶ�˴��������ǿ���ͬʱ���ڵģ�������ͼ��ʾ������˫�ˣ�ÿ��������ͬʱ�л��Ŷ������
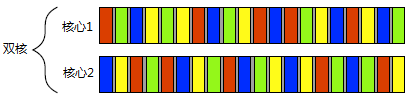
���ֲο������ϸ������˲��кͲ��������������ײ�����ȷָ�����е������������Ķ��߳���Ⱦ�ܹ���API�У������ֲ��кͲ����ĸ�����������������������֮��ĺ��塣
�̳߳��ṩ��һ���µ������ķ�ʽ��������ֻ��Ҫ����һ��ɲ��е�����ͷ���IJ��ԣ������ʹ���̳߳ص������̲߳�����ִ������ʹ�õ����������ֱ�Ӵ��̵߳ĵ��ú���ϸ�ڣ������˵����ߵijɱ���Ҳ�������̵߳ĵ���Ч�ʺ���������
����������һ���̳߳�ʱ�������ؼ��Ե���������Ӱ�첢��Ч�ʣ����磺��ʹ�õ��߳���������Ч��������䷽ʽ���Լ��Ƿ���Ҫ�ȴ�һ��������ɡ�
�̳߳ؿ����Զ���ʵ�֣�Ҳ����ֱ��ʹ��C++������ϵͳ����������ṩ��API��
2.1.3 C++�Ķ��߳�
��C++11֮ǰ��C++�Ķ��߳�֧�ֻ���Ϊ�㣬���ṩ�������ߵ�volatile�ȹؼ��֡�ֱ��C++11�������̲߳���������C++�������ṩ����عؼ��֡�STL���⣬�Ա�ʹ����ʵ�ֿ�ƽ̨�Ķ��̵߳��á�
��Ȼ����ʹ������˵�����̵߳�ʵ�ֿɲ���C++11���߳̿⣬Ҳ���Ը��ݾ����ϵͳƽ̨�ṩ�Ķ��߳�API�Զ����߳̿⣬������ʹ������ACE��boost::thread�ȵ������⡣ʹ��C++�Դ��Ķ��߳̿⣬�м����ŵ㣬һ��ʹ�ü��㣬�����٣����ǿ�ƽ̨�������עϵͳ�ײ㡣
2.1.3.1 C++���̹߳ؼ���
thread_local��C++��ʵ���ֲ߳̾��洢�Ĺؼ��������˴˹ؼ��ֵı�����ζ��ÿ���̶߳����Լ���һ�����ݣ����Ṳ��ͬһ�����ݣ��������ݾ�����
C11�Ĺؼ���_Thread_local���ڶ����ֲ߳̾���������ͷ�ļ�<threads.h>������thread_localΪ�����ؼ��ʵ�ͬ�塣���磺
#include <threads.h>
thread_local int foo = 0;
C++11�����thread_local�ؼ��������������Σ�
1�����ֿռ�(ȫ��)������
2���ļ���̬������
3��������̬������
4����̬��Ա������
���⣬��ͬ�������ṩ�˸��Եķ��������ֲ߳̾�������
// Visual C++, Intel C/C++ (Windows systems), C++Builder, Digital Mars C++
__declspec(thread) int number;
// Solaris Studio C/C++, IBM XL C/C++, GNU C, Clang, Intel C++ Compiler (Linux systems)
__thread int number;
// C++ Builder
int __thread number;
ʹ����volatile���η��ı�����ζ�������ڴ��е�ֵ������ʱ�����仯��Ҳ���߱������������κ��Ż���ÿ��ʹ�õ��˱�����ֵ��������ڴ��ж�ȡ������Ӧ��ֱ��ʹ�üĴ�����ֵ��
�ٸ���������Ӱɡ����������´���Σ�
int a = 10;
volatile int *p = &a;
int b, c;
b = *p;
c = *p;
��pû��volatile���Σ���b = *p��c = *pֻ����ڴ�ȡһ��p��ֵ����ôb��c��ֵ��Ȼ��10��
������volatile��Ӱ�죬����ִ����b = *p���֮��p��ֵ�������߳����ˣ���ִ��c = *p���ٴδ��ڴ��ж�ȡp��ֵ����ʱc��ֵ������10�������µ�ֵ��
���ǣ�volatile�����ܽ�����̵߳�ͬ�����⣬ֻ�ʺ������������ʹ�ã�
1�����źŴ�����signal handler����صij��ϡ�
2�����ڴ�ӳ��Ӳ����memory mapped hardware����صij��ϡ�
3���ͷDZ�����ת��setjmp �� longjmp����صij��ϡ�
�ϸ���˵atomic�����ǹؼ��֣�����STL��ģ���࣬����֧��ָ�����͵�ԭ�Ӳ�����
ʹ��ԭ�ӵ�������ζ�Ÿ����͵�ʵ���Ķ�д��������ԭ���Եģ����������߳��и�Ӷ��ﵽ�̰߳�ȫ��ͬ����Ŀ�ꡣ
������Щ������棬Ϊʲô���ڻ������͵IJ���Ҳ��Ҫԭ�Ӳ��������磺
int cnt = 0;
auto f = [&]{cnt++;};
std::thread t1{f}, t2{f}, t3{f};
���������߳�ͬʱ���ú���f���ú���ִֻ��cnt++����C++ά�ȣ��ƺ�ֻ��һ��ִ����䣬�����ϲ�Ӧ�ô���ͬ�����⡣Ȼ��������ɻ��ָ����ж���ָ���ͻ��ڶ��߳��������߳��������л�������Ԥ֪����Ϊ��
Ϊ�˱����������������Ҫ����atomic���ͣ�
std::atomic<int> cnt{0}; // ��cnt����ԭ�Ӳ�����
auto f = [&]{cnt++;};
std::thread t1{f}, t2{f}, t3{f};
����atomic֮�������߳�ִ�к�Ľ����ȷ���ģ��ܹ�����������������atomic��ʵ�ֻ������ٽ������ƣ���Ч���ϱ��ٽ������졣
Ϊ�˸���һ����˵��C++�ĵ������������ɶ������ָ��ɽ���Compiler Explorer��ʵʱ��̽C++�����ָ�
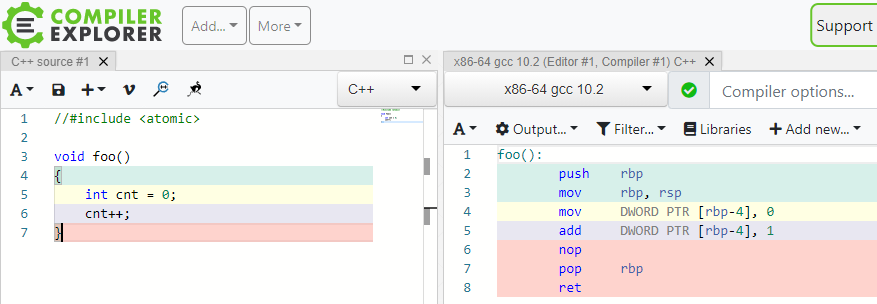
Compiler Explorer��̬�����C++��������Ļ��ָ���ͼ��ʾ��c++����������ܴ���һ�Զ�Ļ��ָ��ɴ�ӡ֤atomicԭ�Ӳ����ı�Ҫ�ԡ�
�������std::atomic�����Ժͽӿڣ�����ʵ�ֺܶ�������������̰߳�ȫ�����ݽṹ���㷨��������һ��������Ķ���ǿ���Ƽ���C++ Concurrency In Action����
2.1.3.2 C++�߳�
C++���߳�������std::thread�����ṩ�Ľӿ����±���
| �ӿ� |
���� |
| join |
�������̣߳�ʹ�����߳�ǿ�Ƶȴ����߳�ִ���ꡣ |
| detach |
�����̷߳��룬ʹ�����߳�����ȴ����߳�ִ���ꡣ |
| swap |
������һ���߳̽����̶߳��� |
| joinable |
��ѯ�Ƿ�ɼ������̡߳� |
| get_id |
��ȡ���̵߳�Ψһ��ʶ���� |
| native_handle |
����ʵ�ֲ���߳̾���� |
| hardware_concurrency |
��̬�ӿڣ�����Ӳ��֧�ֵIJ����߳������� |
ʹ�÷�����
#include <iostream>
#include <thread>
#include <chrono>
void foo()
{
// simulate expensive operation
std::this_thread::sleep_for(std::chrono::seconds(1));
}
int main()
{
std::cout << "starting thread...\n";
std::thread t(foo); // �����̶߳����Ҵ��뱻ִ�еĺ�����
std::cout << "waiting for thread to finish..." << std::endl;
t.join(); // �������̣߳�ʹ�����̱߳���ȴ����߳�ִ����ϡ�
std::cout << "done!\n";
}
�����
starting thread...
waiting for thread to finish...
done!
�����Ҫ�ڵ����̺߳����߳�֮��ͬ�����ݣ������ʹ��C++��std::promise��std::future�Ȼ��ơ�ʾ�����룺
#include <vector>
#include <thread>
#include <future>
#include <numeric>
#include <iostream>
void accumulate(std::vector<int>::iterator first,
std::vector<int>::iterator last,
std::promise<int> accumulate_promise)
{
int sum = std::accumulate(first, last, 0);
accumulate_promise.set_value(sum); // Notify future
}
int main()
{
// Demonstrate using promise<int> to transmit a result between threads.
std::vector<int> numbers = { 1, 2, 3, 4, 5, 6 };
std::promise<int> accumulate_promise;
std::future<int> accumulate_future = accumulate_promise.get_future();
std::thread work_thread(accumulate, numbers.begin(), numbers.end(),
std::move(accumulate_promise));
// future::get() will wait until the future has a valid result and retrieves it.
// Calling wait() before get() is not needed
//accumulate_future.wait(); // wait for result
std::cout << "result = " << accumulate_future.get() << '\n';
work_thread.join(); // wait for thread completion
}
��������
result = 21
���ǣ�std::thread��ִ�в����ܱ�֤���첽�ģ�Ҳ�������ڵ�ǰ�߳�ִ�С�
�����Ҫǿ���첽�����ʹ��std::async��������ָ�������첽��ʽ��std::launch::async��std::launch::deferred��ǰ�߱�ʾʹ���µ��߳��첽��ִ�������߱�ʾ�ڵ�ǰ�߳�ִ�У��һᱻ�ӳ�ִ�С�ʹ�÷�����
#include <iostream>
#include <vector>
#include <algorithm>
#include <numeric>
#include <future>
#include <string>
#include <mutex>
std::mutex m;
struct X {
void foo(int i, const std::string& str) {
std::lock_guard<std::mutex> lk(m);
std::cout << str << ' ' << i << '\n';
}
void bar(const std::string& str) {
std::lock_guard<std::mutex> lk(m);
std::cout << str << '\n';
}
int operator()(int i) {
std::lock_guard<std::mutex> lk(m);
std::cout << i << '\n';
return i + 10;
}
};
template <typename RandomIt>
int parallel_sum(RandomIt beg, RandomIt end)
{
auto len = end - beg;
if (len < 1000)
return std::accumulate(beg, end, 0);
RandomIt mid = beg + len/2;
auto handle = std::async(std::launch::async,
parallel_sum<RandomIt>, mid, end);
int sum = parallel_sum(beg, mid);
return sum + handle.get();
}
int main()
{
std::vector<int> v(10000, 1);
std::cout << "The sum is " << parallel_sum(v.begin(), v.end()) << '\n';
X x;
// Calls (&x)->foo(42, "Hello") with default policy:
// may print "Hello 42" concurrently or defer execution
auto a1 = std::async(&X::foo, &x, 42, "Hello");
// Calls x.bar("world!") with deferred policy
// prints "world!" when a2.get() or a2.wait() is called
auto a2 = std::async(std::launch::deferred, &X::bar, x, "world!");
// Calls X()(43); with async policy
// prints "43" concurrently
auto a3 = std::async(std::launch::async, X(), 43);
a2.wait(); // prints "world!"
std::cout << a3.get() << '\n'; // prints "53"
} // if a1 is not done at this point, destructor of a1 prints "Hello 42" here
ִ�н����
The sum is 10000
43
Hello 42
world!
53
���⣬C++20�Ѿ�֧����������Э�̣�coroutine���ˣ���صĹؼ��֣�co_await��co_return��co_yield����C#�Ƚű����Եĸ�����÷����һ�ޣ�����Ϊ��ʵ�ֻ��ƿ��ܻ����в�ͬ�����IJ�չ��̽���ˡ�
2.1.3.3 C++���߳�ͬ��
�߳�ͬ���Ļ����кܶ࣬C++֧�ֵ������¼��֣�
[2.1.3.1 C++���̹߳ؼ���](#2.1.3.1 C++���̹߳ؼ���)�Ѿ���std::atomic������ϸ�Ľ��������Է�ֹ���߳�֮�乲�����ݵ����ݾ������⡣���⣬�����ṩ�˷ḻ�����Ľӿں�״̬��ѯ���Ա���Ӿ�ϸ��Ч��ͬ��ԭ�����ݣ������ӿںͽ������£�
| �ӿ��� |
���� |
| is_lock_free |
���ԭ�Ӷ����Ƿ������ġ� |
| store |
�洢ֵ��ԭ�Ӷ��� |
| load |
��ԭ�Ӷ������ֵ�� |
| exchange |
��ȡԭ�Ӷ����ֵ�����滻��ָ��ֵ�� |
| compare_exchange_weak, compare_exchange_strong |
��ԭ�Ӷ����ֵ��Ԥ��ֵ��expected���Աȣ������ͬ���滻��Ŀ��ֵ��desired����������true�������ͬ���ͼ���ԭ�Ӷ����ֵ��Ԥ��ֵ��expected����������false��weakģʽ���Ῠ�����̣߳�strongģʽ�Ῠס�����̣߳�ֱ��ԭ�Ӷ����ֵ��Ԥ��ֵ��expected����ͬ�� |
| fetch_add, fetch_sub, fetch_and, fetch_or, fetch_xor |
��ȡԭ�Ӷ����ֵ����������ӡ�����Ȳ����� |
| operator ++, operator --, operator +=, operator -=, ... |
��ԭ�Ӷ�����Ӧ��������������������������ͨ����һ�¡� |
���⣬C++20��֧��wait, notify_one, notify_all��ͬ���ӿڡ�
����compare_exchange_weak�ӿڿ��Ժܷ����ʵ���̰߳�ȫ�ķ�����ʽ�����ݽṹ��ʾ����
#include <atomic>
#include <future>
#include <iostream>
template<typename T>
struct node
{
T data;
node* next;
node(const T& data) : data(data), next(nullptr) {}
};
template<typename T>
class stack
{
public:
std::atomic<node<T>*> head; // ��ջͷ, ����ԭ�Ӳ���.
public:
// ��ջ����
void push(const T& data)
{
node<T>* new_node = new node<T>(data);
// ��ԭ�е�ͷָ����Ϊ�½ڵ����һ�ڵ�.
new_node->next = head.load(std::memory_order_relaxed);
// ���µĽڵ���ϵ�ͷ���ڵ����ԱȲ���, ���new_node->next==head, ˵�������߳�û����head, ���Խ�head�滻��new_node, �Ӷ����push����.
// ��֮, ���new_node->next!=head, ˵�������߳�����head, �������߳��ĵ�head���浽new_node->next, ����ѭ�����.
while(!head.compare_exchange_weak(new_node->next, new_node,
std::memory_order_release,
std::memory_order_relaxed))
; // ��ѭ����
}
};
int main()
{
stack<int> s;
auto r1 = std::async(std::launch::async, &stack<int>::push, &s, 1);
auto r2 = std::async(std::launch::async, &stack<int>::push, &s, 2);
auto r3 = std::async(std::launch::async, &stack<int>::push, &s, 3);
r1.wait();
r2.wait();
r3.wait();
// print the stack's values
node<int>* node = s.head.load(std::memory_order_relaxed);
while(node)
{
std::cout << node->data << " ";
node = node->next;
}
}
�����
2 3 1
�ɴ˿ɼ�������ԭ�Ӽ���ӿڿ��Ժܷ���ؽ��ж��߳�ͬ�������������Ƕ��߳��첽��ջ��ջ��Ԫ�ز�һ��������˳��һ�¡�
���ϴ��뻹�漰�ڴ����˳��ı�ǣ�
- ����һ������(sequentially consistent)��
- ��ȡ-�ͷ�����(memory_order_consume, memory_order_acquire, memory_order_release��memory_order_acq_rel)��
- ��������(memory_order_relaxed)��
�����ⷽ���������Բο���һƪ���ڴ����ϻ��ߡ�C++ concurrency in action�����½�5.3 ͬ��������ǿ������
std::mutex�������������������÷�Χ�ڽ����ٽ�����Critical section����ʹ�øô���Ƭ��ͬʱֻ����һ���̷߳��ʣ��������̳߳���ִ�и�Ƭ��ʱ���ᱻ������std::mutex����std::lock_guard��ʾ�����룺
#include <iostream>
#include <map>
#include <string>
#include <chrono>
#include <thread>
#include <mutex>
std::map<std::string, std::string> g_pages;
std::mutex g_pages_mutex; // ����������
void save_page(const std::string &url)
{
// simulate a long page fetch
std::this_thread::sleep_for(std::chrono::seconds(2));
std::string result = "fake content";
// ���std::lock_guardʹ��, ���Լ�ʱ������ͷŻ�����.
std::lock_guard<std::mutex> guard(g_pages_mutex);
g_pages[url] = result;
}
int main()
{
std::thread t1(save_page, "http://foo");
std::thread t2(save_page, "http://bar");
t1.join();
t2.join();
// safe to access g_pages without lock now, as the threads are joined
for (const auto &pair : g_pages) {
std::cout << pair.first << " => " << pair.second << '\n';
}
}
�����
http://bar => fake content
http://foo => fake content
���⣬�ֶ�����std::mutex�������ͽ���������ʵ��һЩ������Ϊ������ȴ�ij����ǣ�
#include <chrono>
#include <thread>
#include <mutex>
bool flag;
std::mutex m;
void wait_for_flag()
{
std::unique_lock<std::mutex> lk(m); // �������std::unique_lock����std::lock_guard. std::unique_lock����ʵ�ֳ��Ի����, �����ǰ�Լ��������߳�����, ���ӳ�ֱ�������߳��ͷ�, Ȼ��Ż����.
while(!flag)
{
lk.unlock(); // ����������
std::this_thread::sleep_for(std::chrono::milliseconds(100)); // ����100ms���ڴ��ڼ䣬�����߳̿��Խ��뻥�������Ա����flag��ǡ�
lk.lock(); // ����������
}
}
std::condition_variable��std::condition_variable_any������������������C++�����ʵ�֣����Ƕ���Ҫ�뻥�������ʹ�á�����std::condition_variable_any����ͨ�ã����������ϲ�������Ŀ������ʶ���Ӧ�����ȿ���ʹ��std::condition_variable��
�������������Ľӿڣ���ϻ�������ʹ�ã����Ժܷ����ִ���̼߳�ĵȴ���֪ͨ�Ȳ�����ʾ����
#include <iostream>
#include <string>
#include <thread>
#include <mutex>
#include <condition_variable>
std::mutex m;
std::condition_variable cv; // ������������
std::string data;
bool ready = false;
bool processed = false;
void worker_thread()
{
// �ȴ�ֱ�����̸߳ı�readyΪtrue.
std::unique_lock<std::mutex> lk(m);
cv.wait(lk, []{return ready;});
// ����˻���������
std::cout << "Worker thread is processing data\n";
data += " after processing";
// �������ݸ����߳�
processed = true;
std::cout << "Worker thread signals data processing completed\n";
// �ֶ�����, �Ա����̻߳����.
lk.unlock();
cv.notify_one();
}
int main()
{
std::thread worker(worker_thread);
data = "Example data";
// send data to the worker thread
{
std::lock_guard<std::mutex> lk(m);
ready = true;
std::cout << "main() signals data ready for processing\n";
}
cv.notify_one();
// wait for the worker
{
std::unique_lock<std::mutex> lk(m);
cv.wait(lk, []{return processed;});
}
std::cout << "Back in main(), data = " << data << '\n';
worker.join();
}
�����
main() signals data ready for processing
Worker thread is processing data
Worker thread signals data processing completed
Back in main(), data = Example data after processing
C++��future����������һ�ֿ��Է���δ���ķ���ֵ�Ļ��ƣ������ڶ��̵߳�ͬ�������Դ���future�������У� std::async, std::packaged_task, std::promise��
future�������ִ��wait��wait_for��wait_until���Ӷ�ʵ���¼��ȴ���ͬ����ʾ�����룺
#include <iostream>
#include <future>
#include <thread>
int main()
{
// ��packaged_task��ȡ��future
std::packaged_task<int()> task([]{ return 7; }); // wrap the function
std::future<int> f1 = task.get_future(); // get a future
std::thread t(std::move(task)); // launch on a thread
// ��async()��ȡ��future
std::future<int> f2 = std::async(std::launch::async, []{ return 8; });
// ��promise��ȡ��future
std::promise<int> p;
std::future<int> f3 = p.get_future();
std::thread( [&p]{ p.set_value_at_thread_exit(9); }).detach();
// �ȴ�����future
std::cout << "Waiting..." << std::flush;
f1.wait();
f2.wait();
f3.wait();
std::cout << "Done!\nResults are: " << f1.get() << ' ' << f2.get() << ' ' << f3.get() << '\n';
t.join();
}
�����
Waiting...Done!
Results are: 7 8 9
2.1.4 ���߳�ʵ�ֻ���
���̰߳��������ݿɷ�Ϊ���ݲ��к����������֡��������ݲ����Dz�ͬ���߳�Я����ͬ������ִ����ͬ�������������ݲ��е�Ӧ����MMXָ�SIMD������Compute��ɫ���ȡ��������Dz�ͬ���߳�ִ�в�ͬ���������ݿ�����ͬ��Ҳ���Բ�ͬ�����磬��Ϸ���澭�����ļ����ء���Ƶ���������������������ģ�ⶼ�ŵ��������̣߳��Ա����ǿ��Բ��е�ִ�в�ͬ������
���߳�������������Ⱥͷ�ʽ���������Ի��֡��ݹ黮�֡��������ͻ��ֵȡ�
���Ի��ַ������Ӧ�þ��ǽ����������Ԫ��ƽ���ֳ����ɷݣ�ÿ�������ɷ���һ���߳���ִ�У����粢�л���std::for_each��UE���ParallelFor��
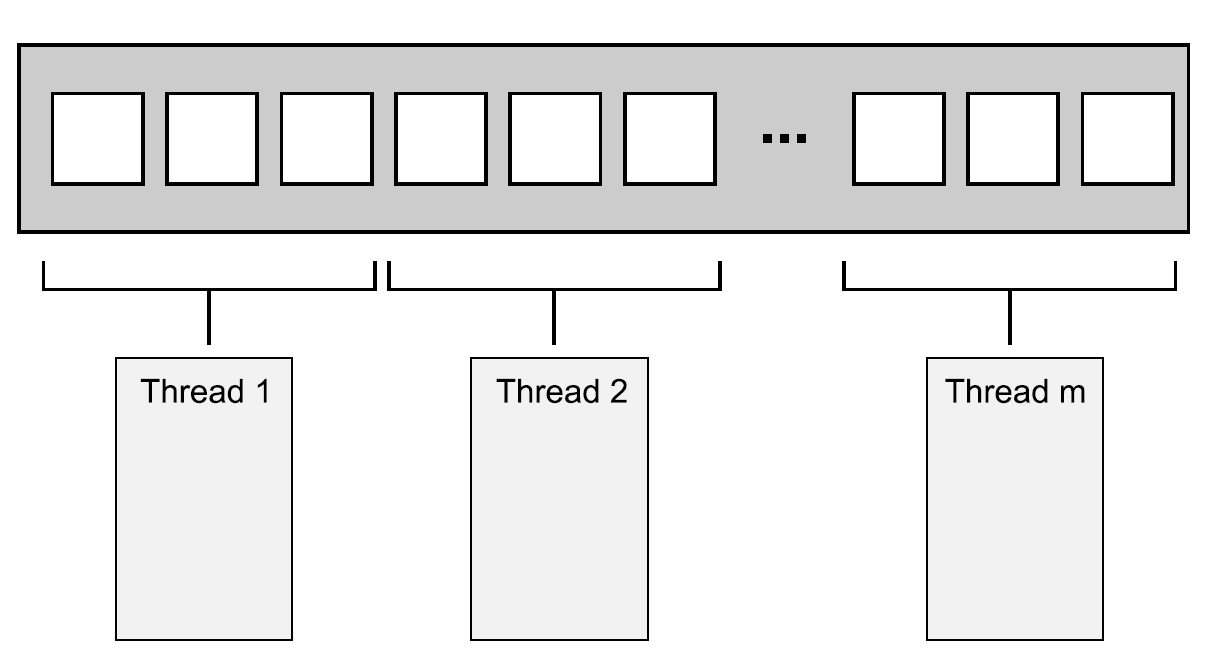
���Ի���ʾ��ͼ���������ݱ�����Ϊ���ɷݣ������ɷ��������߳��в��е�ִ�С�
�����Ի��ֲ���ִ�н�����ͨ����Ҫ�ɵ����̺߳ϲ���ͬ�����еĽ����
�ݹ黮�ַ��ǽ��������ݰ���ij�ֹ��ֳ����ɷݣ�ÿһ���ֿɼ������ֳɸ�ϸ���ȣ�ֱ��ij�ֹ���ֹͣ���֡������ڿ�������
��������������������IJ��裺�����ݻ��ֵ����ࣨpivot��Ԫ��֮ǰ��֮��Ȼ�������Ԫ��֮ǰ��֮������������ٴν��п�����������ֻ����һ��������������֪����Щ��������Ԫ��֮ǰ��֮�����Բ���ͨ�������ݵļ����ԣ����ִﵽ���С���Ҫ�������㷨���в��л�������Ȼ�Ļ��뵽ʹ�õݹ顣ÿһ���ĵݹ鶼���ε���quick_sort��������Ϊ��Ҫ֪����ЩԪ��������Ԫ��֮ǰ��֮��