一、区别
①本质上相同,都是把Map端数据分类处理后交由Reduce的过程。
②数据流有所区别,MR按map, spill, merge, shuffle, sort, r
educe等各阶段逐一实现。Spark基于DAG数据流,可实现更复杂数据流操作(根据宽/窄依赖实现)
③实现功能上有所区别,MR在map中做了排序操作,而Spark假定大多数应用场景Shuffle数据的排序操作不是必须的,而是采用Aggregator机制(Hashmap每个元素<K,V>形式)实现。(下面有较详细说明)
ps:为了减少内存使用,Aggregator是在磁盘进行,也就是说,尽管Spark是“基于内存的计算框架”,但是Shuffle过程需要把数据写入磁盘
二、MR中的Shuffle
在MR框架中,Shuffle是连接Map和Reduce之间的桥梁,Map的输出结果需要经过Shuffle过程之后,也就是经过数据分类以后再交给Reduce进行处理。因此,Shuffle的性能高低直接影响了整个程序的性能和吞吐量。由此可知,Shuffle是指对Map输出结果进行分区、排序、合并等处理并交给Reduce的过程。因此,MapReduce的Shuffle过程分为Map端的操作和Reduce端的操作,如下图:
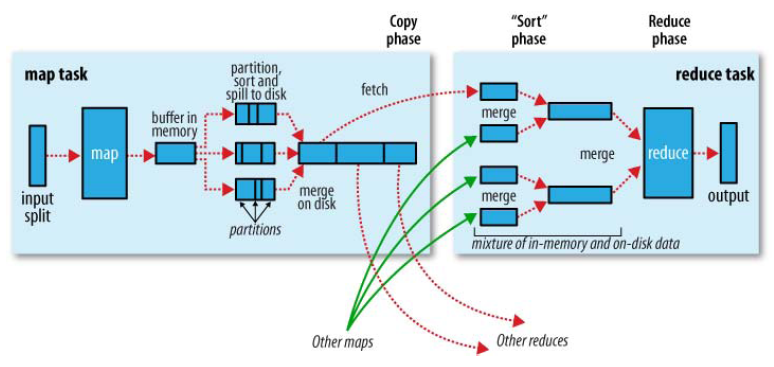
简单点说: Map端Shuffle过程,就是对Map输出结果写入缓存、分区、排序、合并再写入磁盘。
Reduce端Shuffle过程,就是从不同Map机器取回输出进行归并后交给Reduce进行处理。
三、Spark中的Shuffle
①、Spark作为MR框架的改进,也实现了Shuffle的逻辑,如下图:
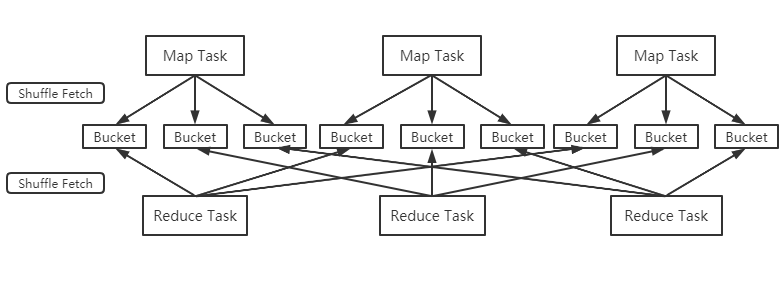
Map端的Shuffle写入(Shuffle Write)方面,每个Map根据Reduce任务的数量创造相应桶数量m*r(桶为抽象概念,m是map任务r是reduce任务),Map任务产生的结果根据分区算法(默认hash)到不同桶中。当Reduce任务启动时,会根据自己任务的id和所依赖的Map任务的id,从远端或本地取得对应的桶,作为Reduce任务的输入进行处理。
ps:在Spark1.2的版本后,Shuffle引擎改为SortShuffleManager(原来为HashShuffleManager),也就是把每个Map任务所有输出数据都写到同一个任务中,避免小文件太多对性能的影响。因此Shuffle过程中,每个Map任务会产生数据文件及所有文件两个。
②、在Reduce端的Shuffle读取(Shuffle Fetch)方面,大多数场景Spark并不在Reduce端做归并和排序,而是采用Aggregator机制。Aggregator本质是个HashMap,其中每个元素都是<K,V>形式。
ps:以词频统计为例,它会将从Map端拉取到的每一个(key,value),更新或插入到HashMap中。若在HashMap中没有查找到这个key,则把这个(key,value)插入其中;若找到这个key,则把value的值累加到V上去。这样就不需要预先把所有的(key,value)进行归并和排序,而是来一个处理一个,避免外部排序这一步骤。
③、窄依赖宽依赖
以是否包含Shuffle操作为判断依据,RDD中的依赖关系可以分为窄依赖与宽依赖,区别如下
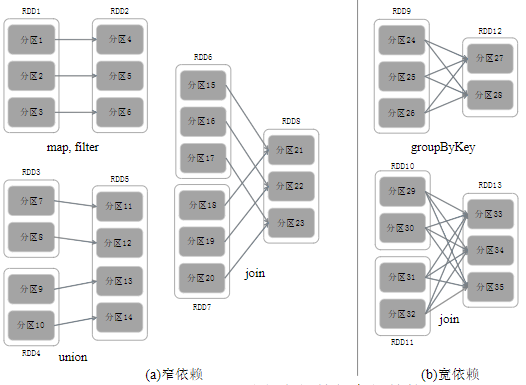
窄依赖:一个父RDD的分区对应一个子RDD的分区,或者多个父RDD的分区对应一个子RDD的分区。典型操作包括map/filter/union等,不会包含Shuffle操作
宽依赖:一个父RDD的一个分区对应一个子RDD的多个分区。典型操作包括groupByKey/sortByKey等,通常包含Shuffle操作
ps:对于join操作,视情况而定,如上图左侧进行协同划分,数据窄依赖。如上图右侧做非协同划分,属于宽依赖。
④、阶段划分
Spark根据DAG图中的RDD依赖关系,把一个作业分成多个阶段。参考下图例子过程:

Stage2为窄依赖,可以把多个fork/join合并为一个,不但减少了大量的全局路障,而且无需保存很多中间结果RDD,可以极大提高性能,该过程叫流水线优化(Pipeline)
学习交流,有任何问题还请随时评论指出交流。