class Model_DIN_V2_Gru_Vec_attGru(Model):
def __init__(self, n_uid, n_mid, n_cat, EMBEDDING_DIM, HIDDEN_SIZE, ATTENTION_SIZE, use_negsampling=False):
super(Model_DIN_V2_Gru_Vec_attGru, self).__init__(n_uid, n_mid, n_cat,
EMBEDDING_DIM, HIDDEN_SIZE, ATTENTION_SIZE,
use_negsampling)
# RNN layer(-s)
with tf.name_scope('rnn_1'):
rnn_outputs, _ = dynamic_rnn(GRUCell(HIDDEN_SIZE), inputs=self.item_his_eb,
sequence_length=self.seq_len_ph, dtype=tf.float32,
scope="gru1")
tf.summary.histogram('GRU_outputs', rnn_outputs)
# Attention layer
with tf.name_scope('Attention_layer_1'):
att_outputs, alphas = din_fcn_attention(self.item_eb, rnn_outputs, ATTENTION_SIZE, self.mask,
softmax_stag=1, stag='1_1', mode='LIST', return_alphas=True)
tf.summary.histogram('alpha_outputs', alphas)
with tf.name_scope('rnn_2'):
rnn_outputs2, final_state2 = dynamic_rnn(VecAttGRUCell(HIDDEN_SIZE), inputs=rnn_outputs,
att_scores = tf.expand_dims(alphas, -1),
sequence_length=self.seq_len_ph, dtype=tf.float32,
scope="gru2")
tf.summary.histogram('GRU2_Final_State', final_state2)
inp = tf.concat([self.uid_batch_embedded, self.item_eb, self.item_his_eb_sum, self.item_eb * self.item_his_eb_sum, final_state2], 1)
self.build_fcn_net(inp, use_dice=True)
然后看看 最新的第三版本。
5.2.2 输入参数
DIEN的输入参数如下,大致可以从注释中知道其意义。
def DIEN(feature_dim_dict, seq_feature_list, embedding_size=8, hist_len_max=16,
gru_type="GRU", use_negsampling=False, alpha=1.0, use_bn=False, dnn_hidden_units=(200, 80),
dnn_activation='relu',
att_hidden_units=(64, 16), att_activation="dice", att_weight_normalization=True,
l2_reg_dnn=0, l2_reg_embedding=1e-6, dnn_dropout=0, init_std=0.0001, seed=1024, task='binary'):
"""Instantiates the Deep Interest Evolution Network architecture.
:param feature_dim_dict: dict,to indicate sparse field (**now only support sparse feature**)like {'sparse':{'field_1':4,'field_2':3,'field_3':2},'dense':[]}
:param seq_feature_list: list,to indicate sequence sparse field (**now only support sparse feature**),must be a subset of ``feature_dim_dict["sparse"]``
:param embedding_size: positive integer,sparse feature embedding_size.
:param hist_len_max: positive int, to indicate the max length of seq input
:param gru_type: str,can be GRU AIGRU AUGRU AGRU
:param use_negsampling: bool, whether or not use negtive sampling
:param alpha: float ,weight of auxiliary_loss
:param use_bn: bool. Whether use BatchNormalization before activation or not in deep net
:param dnn_hidden_units: list,list of positive integer or empty list, the layer number and units in each layer of DNN
:param dnn_activation: Activation function to use in DNN
:param att_hidden_units: list,list of positive integer , the layer number and units in each layer of attention net
:param att_activation: Activation function to use in attention net
:param att_weight_normalization: bool.Whether normalize the attention score of local activation unit.
:param l2_reg_dnn: float. L2 regularizer strength applied to DNN
:param l2_reg_embedding: float. L2 regularizer strength applied to embedding vector
:param dnn_dropout: float in [0,1), the probability we will drop out a given DNN coordinate.
:param init_std: float,to use as the initialize std of embedding vector
:param seed: integer ,to use as random seed.
:param task: str, ``"binary"`` for binary logloss or ``"regression"`` for regression loss
:return: A Keras model instance.
"""
5.2.3 构建向量
这里构建两种向量,分别是密度向量(Dense Vector)和稀疏向量(Spasre Vector)。密度向量会存储所有的值包括零值,而稀疏向量存储的是索引位置及值,不存储零值,在数据量比较大时,稀疏向量才能体现它的优势和价值。
函数get_input是从输入字典中提取向量。
def get_input(feature_dim_dict, seq_feature_list, seq_max_len):
sparse_input, dense_input = create_singlefeat_inputdict(feature_dim_dict)
user_behavior_input = OrderedDict()
for i, feat in enumerate(seq_feature_list):
user_behavior_input[feat] = Input(shape=(seq_max_len,), name='seq_' + str(i) + '-' + feat)
user_behavior_length = Input(shape=(1,), name='seq_length')
return sparse_input, dense_input, user_behavior_input, user_behavior_length
遍历feature_dim_dict构建特征字典,每一个item是name:Embedding。其作用是从sparse_embedding_dict中,获取sparse_input中对应的具体输入变量所对应的embedding。
sparse_embedding_dict = {feat.name: Embedding(feat.dimension, embedding_size,
embeddings_initializer=RandomNormal(
mean=0.0, stddev=init_std, seed=seed),
embeddings_regularizer=l2(
l2_reg_embedding),
name='sparse_emb_' + str(i) + '-' + feat.name) for i, feat in
enumerate(feature_dim_dict["sparse"])}
获取嵌入var,这里每一个embedding_dict[feat]都是一个矩阵。
query_emb_list = get_embedding_vec_list(sparse_embedding_dict, sparse_input, feature_dim_dict["sparse"],
return_feat_list=seq_feature_list)
把这些拼接起来。
query_emb = concat_fun(query_emb_list)
keys_emb = concat_fun(keys_emb_list)
deep_input_emb = concat_fun(deep_input_emb_list)
5.2.4 兴趣进化层
下面开始调用生成兴趣进化层。
hist, aux_loss_1 = interest_evolution(keys_emb, query_emb, user_behavior_length, gru_type=gru_type,
use_neg=use_negsampling, neg_concat_behavior=neg_concat_behavior,
embedding_size=embedding_size, att_hidden_size=att_hidden_units,
att_activation=att_activation,
att_weight_normalization=att_weight_normalization, )
其中:
- DynamicGRU 相当于 第二版的dynamic_rnn,就是第一层 ‘rnn_1’;
- auxiliary_loss与第二版几乎一样;
- auxiliary_net只是最后一步 y_hat = tf.nn.sigmoid(dnn3) 不同;
具体代码如下:
def interest_evolution(concat_behavior, deep_input_item, user_behavior_length, gru_type="GRU", use_neg=False,
neg_concat_behavior=None, embedding_size=8, att_hidden_size=(64, 16), att_activation='sigmoid',
att_weight_normalization=False, ):
aux_loss_1 = None
rnn_outputs = DynamicGRU(embedding_size * 2, return_sequence=True,
name="gru1")([concat_behavior, user_behavior_length])
if gru_type == "AUGRU" and use_neg:
aux_loss_1 = auxiliary_loss(rnn_outputs[:, :-1, :], concat_behavior[:, 1:, :],
neg_concat_behavior[:, 1:, :],
tf.subtract(user_behavior_length, 1), stag="gru") # [:, 1:]
if gru_type == "GRU":
rnn_outputs2 = DynamicGRU(embedding_size * 2, return_sequence=True,
name="gru2")([rnn_outputs, user_behavior_length])
hist = AttentionSequencePoolingLayer(att_hidden_units=att_hidden_size, att_activation=att_activation,
weight_normalization=att_weight_normalization, return_score=False)([
deep_input_item, rnn_outputs2, user_behavior_length])
else: # AIGRU AGRU AUGRU
scores = AttentionSequencePoolingLayer(att_hidden_units=att_hidden_size, att_activation=att_activation,
weight_normalization=att_weight_normalization, return_score=True)([
deep_input_item, rnn_outputs, user_behavior_length])
if gru_type == "AIGRU":
hist = multiply([rnn_outputs, Permute([2, 1])(scores)])
final_state2 = DynamicGRU(embedding_size * 2, gru_type="GRU", return_sequence=False, name='gru2')(
[hist, user_behavior_length])
else: # AGRU AUGRU
final_state2 = DynamicGRU(embedding_size * 2, gru_type=gru_type, return_sequence=False,
name='gru2')([rnn_outputs, user_behavior_length, Permute([2, 1])(scores)])
hist = final_state2
return hist, aux_loss_1
5.2.4.1 DynamicGRU 1
DynamicGRU 相当于 第二版的dynamic_rnn,就是第一层 ‘rnn_1’。
这一层对应架构图中黄色部分,即兴趣抽取层(Interest Extractor Layer),主要组件是 GRU。
主要作用是通过模拟用户的兴趣迁移过程,基于行为序列提取用户兴趣序列。即将用户行为历史的item embedding输入到dynamic rnn(第一层GRU)中。
rnn_outputs = DynamicGRU(embedding_size * 2, return_sequence=True,
name="gru1")([concat_behavior, user_behavior_length])
5.2.4.2 auxiliary_loss
辅助loss的计算其实是一个二分类模型,对应论文中:
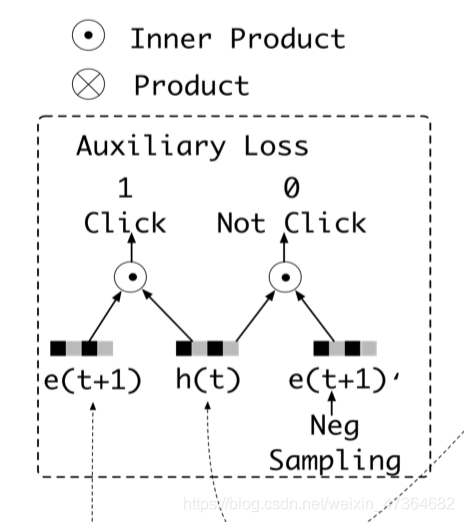
auxiliary_loss与第二版几乎一样。
def auxiliary_loss(h_states, click_seq, noclick_seq, mask, stag=None):
#:param h_states:
#:param click_seq:
#:param noclick_seq: #[B,T-1,E]
#:param mask:#[B,1]
#:param stag:
#:return:
hist_len, _ = click_seq.get_shape().as_list()[1:]
mask = tf.sequence_mask(mask, hist_len)
mask = mask[:, 0, :]
mask = tf.cast(mask, tf.float32)
# 倒数第一维度concat,其余不变
click_input_ = tf.concat([h_states, click_seq], -1)
# 倒数第一维度concat,其余不变
noclick_input_ = tf.concat([h_states, noclick_seq], -1)
# 获取正样本最后一个y_hat
click_prop_ = auxiliary_net(click_input_, stag=stag)[:, :, 0]
# 获取负样本最后一个y_hat
noclick_prop_ = auxiliary_net(noclick_input_, stag=stag)[
:, :, 0] # [B,T-1]
# 对数损失,并且mask出真实历史行为
click_loss_ = - tf.reshape(tf.log(click_prop_),
[-1, tf.shape(click_seq)[1]]) * mask
noclick_loss_ = - \
tf.reshape(tf.log(1.0 - noclick_prop_),
[-1, tf.shape(noclick_seq)[1]]) * mask
loss_ = tf.reduce_mean(click_loss_ + noclick_loss_)
return loss_
5.2.4.3 auxiliary_net
auxiliary_net只是最后一步 y_hat = tf.nn.sigmoid(dnn3) 不同。
def auxiliary_net(in_, stag='auxiliary_net'):
bn1 = tf.layers.batch_normalization(
inputs=in_, name='bn1' + stag, reuse=tf.AUTO_REUSE)
dnn1 = tf.layers.dense(bn1, 100, activation=None,
name='f1' + stag, reuse=tf.AUTO_REUSE)
dnn1 = tf.nn.sigmoid(dnn1)
dnn2 = tf.layers.dense(dnn1, 50, activation=None,
name='f2' + stag, reuse=tf.AUTO_REUSE)
dnn2 = tf.nn.sigmoid(dnn2)
dnn3 = tf.layers.dense(dnn2, 1, activation=None,
name='f3' + stag, reuse=tf.AUTO_REUSE)
y_hat = tf.nn.sigmoid(dnn3)
return y_hat
5.2.4.4 AttentionSequencePoolingLayer
这部分是deepctr完成的,对应第二版本的din_fcn_attention,关于din_fcn_attention可以参见前文[论文解读] 阿里DIEN整体代码结构。
DIEN 中,‘Attention_layer_1’ 层的作用是:通过在兴趣抽取层基础上加入Attention机制,模拟与当前目标广告相关的兴趣进化过程,对与目标物品相关的兴趣演化过程进行建模。即将第一层的输出,喂进第二层GRU,并用attention score(基于第一层的输出向量与候选物料计算得出)来控制第二层的GRU的update gate。
class AttentionSequencePoolingLayer(Layer):
"""The Attentional sequence pooling operation used in DIN.
Input shape
- A list of three tensor: [query,keys,keys_length]
- query is a 3D tensor with shape: ``(batch_size, 1, embedding_size)``
- keys is a 3D tensor with shape: ``(batch_size, T, embedding_size)``
- keys_length is a 2D tensor with shape: ``(batch_size, 1)``
Output shape
- 3D tensor with shape: ``(batch_size, 1, embedding_size)``.
Arguments
- **att_hidden_units**:list of positive integer, the attention net layer number and units in each layer.
- **att_activation**: Activation function to use in attention net.
- **weight_normalization**: bool.Whether normalize the attention score of local activation unit.
- **supports_masking**:If True,the input need to support masking.
References
- [Zhou G, Zhu X, Song C, et al. Deep interest network for click-through rate prediction[C]//Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. ACM, 2018: 1059-1068.](https://arxiv.org/pdf/1706.06978.pdf)
"""
def __init__(self, att_hidden_units=(80, 40), att_activation='sigmoid', weight_normalization=False,
return_score=False,
supports_masking=False, **kwargs):
self.att_hidden_units = att_hidden_units
self.att_activation = att_activation
self.weight_normalization = weight_normalization
self.return_score = return_score
super(AttentionSequencePoolingLayer, self).__init__(**kwargs)
self.supports_masking = supports_masking
def build(self, input_shape):
if not self.supports_masking:
if not isinstance(input_shape, list) or len(input_shape) != 3:
raise ValueError('...)
if len(input_shape[0]) != 3 or len(input_shape[1]) != 3 or len(input_shape[2]) != 2:
raise ValueError(...)
if input_shape[0][-1] != input_shape[1][-1] or input_shape[0][1] != 1 or input_shape[2][1] != 1:
raise ValueError(...)
else:
pass
self.local_att = LocalActivationUnit(
self.att_hidden_units, self.att_activation, l2_reg=0, dropout_rate=0, use_bn=False, seed=1024, )
super(AttentionSequencePoolingLayer, self).build(
input_shape) # Be sure to call this somewhere!
def call(self, inputs, mask=None, training=None, **kwargs):
if self.supports_masking:
if mask is None:
raise ValueError(...)
queries, keys = inputs
key_masks = tf.expand_dims(mask[-1], axis=1)
else:
queries, keys, keys_length = inputs
hist_len = keys.get_shape()[1]
key_masks = tf.sequence_mask(keys_length, hist_len)
attention_score = self.local_att([queries, keys], training=training)
outputs = tf.transpose(attention_score, (0, 2, 1))
if self.weight_normalization:
paddings = tf.ones_like(outputs) * (-2 ** 32 + 1)
else:
paddings = tf.zeros_like(outputs)
outputs = tf.where(key_masks, outputs, paddings)
if self.weight_normalization:
outputs = tf.nn.softmax(outputs)
if not self.return_score:
outputs = tf.matmul(outputs, keys)
outputs._uses_learning_phase = attention_score._uses_learning_phase
return outputs