逻辑回归
主要是给出“是”和“否”的回答,使用Sigmoid激活函数:

需要用到激活函数:Sigmoid函数,将输入数据控制在0到1之间并输出。
将0到1之间的值可以看着是一种概率值,当概率值小于0.5时,输出了一个负面的回答;当概率值大于0.5时,认为它给出了一个正面的回答。sigmoid是一个概率分布函数,给定某个输入,它将输出为一个概率值。把这种0到1之间的值看作是这个网络给出的概率结果
逻辑回归损失函数
平方差损失所反映的是损失和原有数据集在同一数量级的情形,对于庞大的数据集而言,需要迭代次数更多,训练更久。对于分类问题,我们最好是使用交叉熵的损失函数会有更好的效果,交叉熵会输出一个更大的“损失”
交叉熵损失函数
交叉熵刻画的是实际输出概率与期望输出概率的距离,也就是交叉熵的值越小,两个概率分布就越接近。假设分布p为期望输出,概率分布q为实际输出,H(p,q)为交叉熵,则有
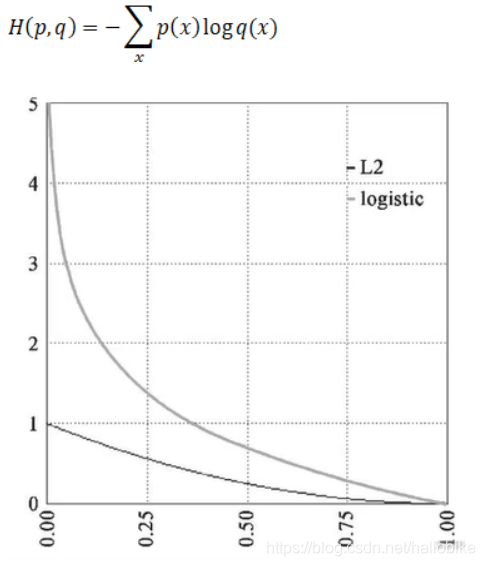
靠近0时,logistic损失非常大,而L2损失非常小,只能到1。所以说交叉熵损失它放大了这个损失。
keras交叉熵
在Keras里,使用binary_crossentropy来计算二元交叉熵。
逻辑回归代码例子:
"""
Author: LGD
FileName: logistic_regression
DateTime: 2020/10/26 20:49
SoftWare: PyCharm
"""
"""
线性回归预测是的一个连续的值
逻辑回归给出的是“是”和“否”的回答,二元分类问题。
需要用到激活函数:Sigmoid函数,将输入数据控制在0到1之间并输出。
将0到1之间的值可以看着是一种概率值,当概率值小于0.5时,输出了一个负面的回答;
当概率值大于0.5时,认为它给出了一个正面的回答。sigmoid是一个概率分布函数,给定某个输入,它将输出为一个概率值。
把这种0到1之间的值看作是这个网络给出的概率结果
逻辑回归损失函数
平方差损失所反映的是损失和原有数据集在同一数量级的情形,对于庞大的数据集而言,需要迭代次数更多,训练更久。
对于分类问题,我们最好是使用交叉熵的损失函数会有更好的效果,
交叉熵会输出一个更大的“损失”
交叉熵损失函数
交叉熵刻画的是实际输出概率与期望输出概率的距离,也就是交叉熵的值越小,两个概率分布就越接近。
假设分布p为期望输出,概率分布q为实际输出,H(p,q)为交叉熵,则有
H(p,q)=-(对x求和)p(x)log(q(x))
keras交叉熵
在Keras里,使用binary_crossentropy来计算二元交叉熵。
"""
"""
逻辑回归实现
"""
import tensorflow as tf
import pandas as pd
import matplotlib.pyplot as plt
data = pd.read_csv("datasets/credit-a.csv", header=None)
print(data.head())
last_column = data.iloc[:, -1].value_counts()
print(last_column)
x = data.iloc[:, :-1]
y = data.iloc[:, -1].replace(-1, 0)
model = tf.keras.Sequential()
model.add(tf.keras.layers.Dense(4, input_shape=(15,), activation='relu'))
model.add(tf.keras.layers.Dense(4, activation='relu'))
model.add(tf.keras.layers.Dense(1, activation='sigmoid'))
model.summary()
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=["acc"]
)
history = model.fit(x, y, epochs=100)
print(history.history.keys())
plt.plot(history.epoch, history.history.get('loss'))
plt.show()
plt.plot(history.epoch, history.history.get('acc'))
plt.show()
cs