жїГЩЗжЗжЮіЃЈPrincipal Components AnalysisЃЌPCAЃЉЪЧвЛжжЪ§ОнНЕЮЌММЪѕЃЌЭЈЙ§е§НЛБфЛЛНЋвЛзщЯрЙиадИпЕФБфСПзЊЛЛЮЊНЯЩйЕФБЫДЫЖРСЂЁЂЛЅВЛЯрЙиЕФБфСПЃЌДгЖјМѕЩйЪ§ОнЕФЮЌЪ§ЁЃ
1ЁЂЪ§ОнНЕЮЌ
1.1 ЮЊЪВУДвЊНјааЪ§ОнНЕЮЌЃП
ЁЁЁЁЮЊЪВУДвЊНјааЪ§ОнНЕЮЌЃПНЕЮЌЕФКУДІЪЧвдТдЕЭЕФОЋЖШЛЛШЁЮЪЬтЕФМђЛЏЁЃ
ЁЁЁЁШЫУЧдкбаОПЮЪЬтЪБЃЌЮЊСЫШЋУцЁЂзМШЗЕиЗДгГЪТЮяЕФЬиеїМАЦфЗЂеЙЙцТЩЃЌЭљЭљвЊПМТЧКмЖрЯрЙижИБъЕФБфЛЏКЭгАЯьЁЃгШЦфдкЪ§ОнЭкОђКЭЗжЮіЙЄзїжаЃЌЧАЦкЪеМЏЪ§ОнНзЖЮзмЪЧОЁСПЪеМЏФмЙЛЛёЕУЕФИїжжЪ§ОнЃЌФмЪеОЁЪеЃЌБмУтвХТЉЁЃЖрБфСПЁЂДѓбљБОЕФЪ§ОнЮЊКѓЦкЕФбаОПКЭгІгУЬсЙЉСЫЗсИЛЕФаХЯЂЃЌДгВЛЭЌНЧЖШЗДгГСЫЮЪЬтЕФЬиеїКЭаХЯЂЃЌЕЋвВИјЪ§ОнДІРэКЭЗжЮіЙЄзїДјРДСЫКмЖрРЇФбЁЃ
ЁЁЁЁЮЊСЫБмУтвХТЉаХЯЂашвЊЛёШЁОЁПЩФмЖрЕФЬиеїБфСПЃЌЕЋЪЧЙ§ЖрЕФБфСПгжМгОчСЫЮЪЬтЕФИДдгадЁЃгЩгкИїжжБфСПЖМЪЧЖдЭЌвЛЪТЮяЕФЗДгГЃЌБфСПжЎМфОГЃЛсДцдквЛЖЈЕФЯрЙиадЃЌетОЭдьГЩДѓСПЕФаХЯЂжиИДЁЂжиЕўЃЌгаЪБЛсбЭУЛЩѕжСХЄЧњЪТЮяЕФеце§ЬиеїгыФкдкЙцТЩЁЃвђДЫЃЌЮвУЧЯЃЭћЪ§ОнЗжЮіжаЩцМАЕФБфСПНЯЩйЃЌЖјЕУЕНЕФаХЯЂСПгжНЯЖрЁЃетОЭашвЊЭЈЙ§НЕЮЌЗНЗЈЃЌдкМѕЩйашвЊЗжЮіЕФБфСПЪ§СПЕФЭЌЪБЃЌОЁПЩФмЖрЕФБЃСєжкЖрдЪМБфСПЫљАќКЌЕФгааЇаХЯЂЁЃ
ЁЁЁЁБфСПжЎМфОпгавЛЖЈЕФЯрЙиЙиЯЕЃЌвтЮЖзХЯрЙиБфСПЫљЗДгГЕФаХЯЂгавЛЖЈГЬЖШЕФжиЕўЃЌОЭгаПЩФмгУНЯЩйЕФзлКЯжИБъОлКЯЁЂЗДгГжкЖрдЪМБфСПЫљАќКЌЕФШЋВПаХЯЂЛђжївЊаХЯЂЁЃ вђДЫЃЌашвЊбаОПЬиеїБфСПжЎМфЕФЯрЙиадЁЂЯрЫЦадЃЌвдМѕЩйЬиеїБфСПЕФЪ§СПЃЌБугкЗжЮігАЯьЯЕЭГЕФжївЊвђЫиЁЃР§ШчЃЌЖдбЇЩњЕФЦРМлжИБъгаКмЖрЃЌзївЕЁЂПМЧкЁЂЛюЖЏЁЂНБГЭЁЂПМЪдЁЂПМКЫЃЌИљОнИїжжжИБъЕФЙиСЊЖШКЭЯрЫЦадЃЌзюжеПЩвдОлКЯЮЊЕТжЧЬхУРЕШМИИіжївЊЕФРрБ№жИБъЗДгГжкЖржИБъжаДѓВПЗжаХЯЂЁЃ
ЁЁЁЁ
ЁЁЁЁНЕЮЌЗНЗЈПЩвдДгЪТЮяжЎМфДэзлИДдгЕФЙиЯЕжаевГівЛаЉжївЊвђЫиЃЌДгЖјФмгааЇРћгУДѓСПЭГМЦЪ§ОнНјааЖЈСПЗжЮіЃЌНтЪЭБфСПжЎМфЕФФкдкЙиЯЕЃЌЕУЕНЖдЪТЮяЬиеїМАЦфЗЂеЙЙцТЩЕФвЛаЉЩюВуДЮЕФЦєЗЂЁЃ
1.2 ГЃгУЕФНЕЮЌЫМЯыКЭЗНЗЈ
ЁЁЁЁНЕЮЌЕФЪ§бЇБОжЪЪЧНЋИпЮЌЬиеїПеМфгГЩфЕНЕЭЮЌЬиеїПеМфЃЌгаЯпадгГЩфКЭЗЧЯпадгГЩфСНРржївЊЗНЗЈЁЃ
ЁЁЁЁЯпадгГЩфЗНЗЈжївЊгажїГЩЗжЗжЮіЃЈPCAЃЉКЭЯпадХаБ№КЏЪ§ЃЈLDAЃЉЁЃжїГЩЗжЗжЮіЃЈPCAЃЉЕФЫМЯыЪЧАДОљЗНЮѓВюЫ№ЪЇзюаЁЛЏддђЃЌНЋИпЮЌдЪМПеМфБфЛЛЕНЕЭЮЌЬиеїЯђСППеМфЁЃЯпадХаБ№КЏЪ§ЃЈLDAЃЉЕФЫМЯыЪЧЯђЯпадХаБ№ГЌЦНУцЕФЗЈЯђСПЩЯЭЖгАЃЌЪЙЕУЧјЗжЖШзюДѓЃЈИпФкОлЃЌЕЭёюКЯЃЉ ЁЃ
ЁЁЁЁЗЧЯпадгГЩфЗНЗЈжївЊгаЃКЛљгкКЫЕФЗЧЯпадНЕЮЌЃЌ НЋИпЮЌЯђСПЕФФкЛ§зЊЛЛГЩЕЭЮЌЕФКЫКЏЪ§БэЪОЃЌШчКЫжїГЩЗжЗжЮіЃЈKPCAЃЉЁЂКЫЯпадХаБ№КЏЪ§ЃЈKLDAЃЉ ЃЛЖўЮЌЛЏКЭеХСПЛЏЃЌ НЋЪ§ОнгГЩфЕНЖўЮЌПеМфЩЯЃЌШчЖўЮЌжїГЩЗжЗжЮіЃЈ2DPCAЃЉЁЂЖўЮЌЯпадХаБ№ЗжЮіЃЈ2DLDAЃЉЁЂЖўЮЌЕфаЭЯрЙиЗжЮіЃЈ2DCCAЃЉЃЛСїаЮбЇЯАЗНЗЈЃЌ ДгИпЮЌВЩбљЪ§ОнжаЛжИДЕЭЮЌСїаЮНсЙЙВЂЧѓГіЯргІЕФЧЖШыгГЩфЃЌШчЕШОргГЩф ЃЈISOMapЃЉ ЃЌ РЦеРЫЙЬиеїгГЩф ЃЈLEЃЉЃЌ ОжВПЯпадЧЖШы ЃЈLPPЃЉЁЃБОжЪЩЯЃЌЗЧЯпадгГЩфЕФЫМЯыКЭЫуЗЈгыЩёОЭјТчЪЧЯрЭЈЕФЁЃ
ЁЁЁЁДЫЭтЃЌЛЙПЩвдЭЈЙ§ОлРрЗжЮіЁЂЩёОЭјТчЗНЗЈНјааЪ§ОнНЕЮЌЁЃ
1.3 SKlearn жаЕФНЕЮЌЗжЮіЗНЗЈ
ЁЁЁЁSKlearn ЙЄОпАќЬсЙЉСЫЖржжНЕЮЌЗжЮіЗНЗЈЁЃ
- жїГЩЗжЗжЮіЁЁЁЁ
- decomposition.PCAЁЁЁЁжїГЩЗжЗжЮі
- decomposition.IncrementalPCAЁЁЁЁдіСПжїГЩЗжЗжЮі
- decomposition.KernelPCAЁЁЁЁКЫжїГЩЗжЗжЮі
- decomposition.SparsePCAЁЁЁЁЯЁЪшжїГЩЗжЗжЮі
- decomposition.MiniBatchSparsePCAЁЁЁЁаЁХњСПЯЁЪшжїГЩЗжЗжЮі
- decomposition.TruncatedSVDЁЁЁЁНиЖЯЦцвьжЕЗжНт
- зжЕфбЇЯА
- decomposition.DictionaryLearningЁЁЁЁзжЕфбЇЯА
- decomposition.MiniBatchDictionaryLearningЁЁЁЁаЁХњСПзжЕфбЇЯА
- decomposition.dict_learningЁЁЁЁзжЕфбЇЯАгУгкОиеѓЗжНт
- decomposition.dict_learning_onlineЁЁЁЁдкЯпзжЕфбЇЯАгУгкОиеѓЗжНт
- вђзгЗжЮі
- decomposition.FactorAnalysisЁЁЁЁвђзгЗжЮіЃЈFAЃЉ
- ЖРСЂГЩЗжЗжЮі
- decomposition.FastICAЁЁЁЁПьЫйЖРСЂГЩЗжЗжЮі
- ЗЧИКОиеѓЗжНт
- decomposition.NMFЁЁЁЁЗЧИКОиеѓЗжНт
- вўЪНЕвРћПЫРГЗжВМ
- decomposition.LatentDirichletAllocationЁЁЁЁдкЯпБфЗжБДвЖЫЙЫуЗЈЃЈвўЪНЕвРћПЫРГЗжВМЃЉ
2ЁЂжїГЩЗжЗжЮіЃЈPCAЃЉЗНЗЈ
2.1 ЛљБОЫМЯыКЭдРэ
ЁЁЁЁжїГЩЗжЗжЮіЪЧзюЛљДЁЪ§ОнНЕЮЌЗНЗЈЃЌЫќжЛашвЊЬиеїжЕЗжНтЃЌОЭПЩвдЖдЪ§ОнНјаабЙЫѕЁЂШЅдыЃЌгІгУЪЎЗжЙуЗКЁЃ
ЁЁЁЁжїГЩЗжЗжЮіЕФФПЕФЪЧМѕЩйЪ§ОнМЏБфСПЪ§СПЃЌЭЌЪБвЊБЃСєОЁПЩФмЖрЕФЬиеїаХЯЂЃЛЗНЗЈЪЧЭЈЙ§е§НЛБфЛЛНЋдЪМБфСПзщзЊЛЛЮЊЪ§СПНЯЩйЕФБЫДЫЖРСЂЕФЬиеїБфСПЃЌДгЖјМѕЩйЪ§ОнМЏЕФЮЌЪ§ЁЃ
ЁЁЁЁжїГЩЗжЗжЮіЗНЗЈЕФЫМЯыЪЧЃЌНЋИпЮЌЬиеїЃЈnЮЌЃЉгГЩфЕНЕЭЮЌПеМфЃЈkЮЌЃЉЩЯЃЌаТЕФЕЭЮЌЬиеїЪЧдкдгаЕФИпЮЌЬиеїЛљДЁЩЯЭЈЙ§ЯпадзщКЯЖјжиЙЙЕФЃЌВЂОпгаЯрЛЅе§НЛЕФЬиадЃЌМДЮЊжїГЩЗжЁЃ
ЁЁЁЁЭЈЙ§е§НЛБфЛЛЙЙдьБЫДЫе§НЛЕФаТЕФЬиеїЯђСПЃЌетаЉЬиеїЯђСПзщГЩСЫаТЕФЬиеїПеМфЁЃНЋЬиеїЯђСПАДЬиеїжЕХХађКѓЃЌбљБОЪ§ОнМЏжаЫљАќКЌЕФШЋВПЗНВюЃЌДѓВПЗжОЭАќКЌдкЧАМИИіЬиеїЯђСПжаЃЌЦфКѓЕФЬиеїЯђСПЫљКЌЕФЗНВюКмаЁЁЃвђДЫЃЌПЩвджЛБЃСєЧА kИіЬиеїЯђСПЃЌЖјКіТдЦфЫќЕФЬиеїЯђСПЃЌЪЕЯжЖдЪ§ОнЬиеїЕФНЕЮЌДІРэЁЃ
ЁЁЁЁжїГЩЗжЗжЮіЗНЗЈЕУЕНЕФжїГЩЗжБфСПОпгаМИИіЬиЕуЃКЃЈ1ЃЉУПИіжїГЩЗжБфСПЖМЪЧдЪМБфСПЕФЯпадзщКЯЃЛЃЈ2ЃЉжїГЩЗжЕФЪ§ФПДѓДѓЩйгкдЪМБфСПЕФЪ§ФПЃЛЃЈ3ЃЉжїГЩЗжБЃСєСЫдЪМБфСПЕФОјДѓЖрЪ§аХЯЂЃЛЃЈ4ЃЉИїжїГЩЗжБфСПжЎМфБЫДЫЯрЛЅЖРСЂЁЃ
2.2 ЫуЗЈВНжш
ЁЁЁЁжїГЩЗжЗжЮіЕФЛљБОВНжшЪЧЃКЖддЪМЪ§ОнЙщвЛЛЏДІРэКѓЧѓаЗНВюОиеѓЃЌдйЖдаЗНВюОиеѓЧѓЬиеїЯђСПКЭЬиеїжЕЃЛЖдЬиеїЯђСПАДЬиеїжЕДѓаЁХХађКѓЃЌвРДЮбЁШЁЬиеїЯђСПЃЌжБЕНбЁдёЕФЬиеїЯђСПЕФЗНВюеМБШТњзувЊЧѓЮЊжЙЁЃ
ЁЁЁЁЫуЗЈЕФЛљБОСїГЬШчЯТЃК
- ЃЈ1ЃЉЙщвЛЛЏДІРэЃЌЪ§ОнМѕШЅЦНОљжЕЃЛ
- ЃЈ2ЃЉЭЈЙ§ЬиеїжЕЗжНтЃЌМЦЫуаЗНВюОиеѓЃЛ
- ЃЈ3ЃЉМЦЫуаЗНВюОиеѓЕФЬиеїжЕКЭЬиеїЯђСПЃЛ
- ЃЈ4ЃЉНЋЬиеїжЕДгДѓЕНаЁХХађЃЛ
- ЃЈ5ЃЉвРДЮбЁШЁЬиеїжЕзюДѓЕФkИіЬиеїЯђСПзїЮЊжїГЩЗжЃЌжБЕНЦфРлМЦЗНВюЙБЯзТЪДяЕНвЊЧѓЃЛ
- ЃЈ6ЃЉНЋдЪМЪ§ОнгГЩфЕНбЁШЁЕФжїГЩЗжПеМфЃЌЕУЕННЕЮЌКѓЕФЪ§ОнЁЃ
ЁЁЁЁдкЫуЗЈЪЕЯжЕФЙ§ГЬжаЃЌSKlearn ЙЄОпАќеыЖдЪЕМЪЮЪЬтЕФЬиЪтадЃЌгжЗЂеЙСЫИїжжИФНјЫуЗЈЃЌР§ШчЃК
- діСПжїГЩЗжЗжЮіЃКеыЖдДѓаЭЪ§ОнМЏЃЌЮЊСЫНтОіФкДцЯожЦЮЪЬтЃЌНЋЪ§ОнЗжГЩЖрХњЃЌЭЈЙ§діСПЗНЪНж№ВНЕїгУжїГЩЗжЗжЮіЫуЗЈЃЌзюжеЭъГЩећИіЪ§ОнМЏЕФНЕЮЌЁЃ
- КЫжїГЩЗжЗжЮіЃКеыЖдЯпадВЛПЩЗжЕФЪ§ОнМЏЃЌЪЙгУЗЧЯпадЕФКЫКЏЪ§АббљБОПеМфгГЩфЕНЯпадПЩЗжЕФИпЮЌПеМфЃЌШЛКѓдкетИіИпЮЌПеМфНјаажїГЩЗжЗжЮіЁЃ
- ЯЁЪшжїГЩЗжЗжЮіЃКеыЖджїГЩЗжЗжЮіНсЙћНтЪЭадШѕЕФЮЪЬтЃЌЭЈЙ§ЬсШЁзюФмжиНЈЪ§ОнЕФЯЁЪшЗжСПЃЌ ЭЙЯджїГЩЗжжаЕФжївЊзщГЩВПЗжЃЌШнвзНтЪЭФФаЉдЪМБфСПЕМжТСЫбљБОжЎМфЕФВювьЁЃЁЁ
2.3 гХЕуКЭШБЕу
ЁЁЁЁжїГЩЗжЗжЮіЗНЗЈЕФжївЊгХЕуЪЧЃК
ЁЁЁЁ1ЃЉНівдЗНВюКтСПаХЯЂСПЃЌВЛЪмЪ§ОнМЏвдЭтЕФвђЫигАЯьЃЛЁЁ
ЁЁЁЁ2ЃЉИїжїГЩЗжжЎМфе§НЛЃЌПЩЯћГ§дЪМЪ§ОнИїБфСПжЎМфЕФЯрЛЅгАЯьЃЛ
ЁЁЁЁ3ЃЉЗНЗЈМђЕЅЃЌвзгкЪЕЯжЁЃ
ЁЁЁЁжїГЩЗжЗжЮіЗНЗЈЕФжївЊШБЕуЪЧЃК
ЁЁЁЁ1ЃЉИїИіжїГЩЗжЕФКЌвхОпгаФЃК§ЃЌНтЪЭадШѕЃЌЭЈГЃжЛгааХЯЂСПЖјЮоЪЕМЪКЌвхЃЛ
ЁЁЁЁ2ЃЉдкбљБОЗЧе§ЬЌЗжВМЪБЕУЕНЕФжїГЩЗжВЛЪЧзюгХЕФЃЌвђДЫЬиЪтЧщПіЯТЗНВюаЁЕФГЩЗжвВПЩФмКЌгаживЊаХЯЂЁЃЁЁЁЁ
3ЁЂSKlearn жаЕФжїГЩЗжЗжЮіЃЈPCAЃЉ ЗНЗЈ
3.1 PCA ЫуЗЈЃЈdecomposition.PCAЃЉ
ЁЁЁЁsklearn.decomposition.PCA РрЪЧ PCAЫуЗЈЕФОпЬхЪЕЯжЃЌЙйЭјНщЩмЯъМћЃКhttps://scikit-learn.org/stable/modules/decomposition.html
sklearn.decomposition.PCA(n_components=None, copy=True, whiten=False)
class sklearn.decomposition.PCA(n_components=None, *, copy=True, whiten=False, svd_solver='auto', tol=0.0, iterated_power='auto', random_state=None)
ЁЁЁЁPCA РрЕФжївЊВЮЪ§ЃК
- n_components: int,floatЁЁЁЁn ЮЊе§ећЪ§ЃЌжИБЃСєжїГЩЗжЕФЮЌЪ§ЃЛn ЮЊ (0,1] ЗЖЮЇЕФЪЕЪ§ЪБЃЌБэЪОжїГЩЗжЕФЗНВюКЭЫљеМЕФзюаЁуажЕЁЃ
- whitenЃКbool, default=FalseЁЁЁЁЪЧЗёЖдНЕЮЌКѓЕФжїГЩЗжБфСПНјааЙщвЛЛЏЁЃФЌШЯжЕ FalseЁЃ
- svd_solverЃК{ЁЎautoЁЏ, ЁЎfullЁЏ, ЁЎarpackЁЏ, ЁЎrandomizedЁЏ}ЁЁЁЁжИЖЈЦцвьжЕЗжНтSVDЕФЫуЗЈЁЃ'full' ЕїгУ scipyПтЕФ SVDЃЛ'arpack'ЕїгУscipyПтЕФ sparse SVDЃЛ'randomized' SKlearnЕФSVDЃЌЪЪгУгкЪ§ОнСПДѓЁЂБфСПЮЌЖШЖрЁЂжїГЩЗжЮЌЪ§ЕЭЕФГЁОАЁЃФЌШЯжЕ 'auto'ЁЃ
ЁЁЁЁPCA РрЕФжївЊЪєадЃК
- components_ЃК ЁЁЁЁЗНВюзюДѓЕФ n-components ИіжїГЩЗж
- explained_variance_ЃКЁЁЁЁИїИіжїГЩЗжЕФЗНВюжЕ
- explained_variance_ratio_ЃКЁЁЁЁИїИіжїГЩЗжЕФЗНВюжЕеМжїГЩЗжЗНВюКЭЕФБШР§
ЁЁЁЁPCA РрЕФжївЊЗНЗЈЃК
- fit(X,y=None)ЁЁЁЁБэЪОгУЪ§Он X бЕСЗPCAФЃаЭ
fit() ЪЧscikit-learnжаЕФЭЈгУЗНЗЈЃЌЪЕЯжбЕСЗЁЂФтКЯЕФВНжшЁЃPCAЪЧЮоМрЖНбЇЯАЃЌy=NoneЁЃ
- fit_transform(X)ЁЁЁЁБэЪОгУЪ§Он X бЕСЗPCAФЃаЭЃЌВЂЗЕЛиНЕЮЌКѓЕФЪ§Он
- transform(X)ЁЁЁЁНЋЪ§Он X зЊЛЛГЩНЕЮЌКѓЕФЪ§ОнЃЌгУбЕСЗКУЕФ PCAФЃаЭЖдаТЕФЪ§ОнМЏНјааНЕЮЌЁЃ
- inverse_transform()ЁЁЁЁНЋНЕЮЌКѓЕФЪ§ОнзЊЛЛГЩдЪМЪ§Он
3.2 decomposition.PCA ЪЙгУР§ГЬ
from sklearn.decomposition import PCA # ЕМШы sklearn.decomposition.PCA Рр
import numpy as np
X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]])
modelPCA = PCA(n_components=2) # НЈСЂФЃаЭЃЌЩшЖЈБЃСєжїГЩЗжЪ§ K=2
modelPCA.fit(X) # гУЪ§ОнМЏ X бЕСЗ ФЃаЭ modelPCA
print(modelPCA.n_components_) # ЗЕЛи PCA ФЃаЭБЃСєЕФжїГЩЗнИіЪ§
# 2
print(modelPCA.explained_variance_ratio_) # ЗЕЛи PCA ФЃаЭИїжїГЩЗнеМБШ
# [0.9924 0.0075] # print ЯдЪОНсЙћ
print(modelPCA.singular_values_) # ЗЕЛи PCA ФЃаЭИїжїГЩЗнЕФЦцвьжЕ
# [6.3006 0.5498] # print ЯдЪОЗжРрНсЙћ
X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]])
modelPCA2 = PCA(n_components=0.9) # НЈСЂФЃаЭЃЌЩшЖЈжїГЩЗнЗНВюеМБШ 0.9
# гУЪ§ОнМЏ X бЕСЗ ФЃаЭ modelPCA2ЃЌВЂЗЕЛиНЕЮЌКѓЕФЪ§Он
Xtrans = modelPCA2.fit_transform(X)
print(modelPCA2.n_components_) # ЗЕЛи PCA ФЃаЭБЃСєЕФжїГЩЗнИіЪ§
# 1
print(modelPCA2.explained_variance_ratio_) # ЗЕЛи PCA ФЃаЭИїжїГЩЗнеМБШ
# [0.9924] # print ЯдЪОНсЙћ
print(modelPCA2.singular_values_) # ЗЕЛи PCA ФЃаЭИїжїГЩЗнеМБШ
# [6.3006] # print ЯдЪОНсЙћ
print(Xtrans) # ЗЕЛиНЕЮЌКѓЕФЪ§Он Xtrans
# [[1.3834], [2.2219], [3.6053], [-1.3834], [-2.2219], [-3.6053]]
ЁЁЁЁзЂвтЃКНЈСЂФЃаЭЪБЃЌPCA(n_components=2) жаЕФ n_componentsЮЊе§ећЪ§ЃЌБэЪОЩшЖЈБЃСєЕФжїГЩЗнЮЌЪ§ЮЊ 2ЃЛPCA(n_components=0.9) жаЕФ n_components ЮЊ (0,1] ЕФаЁЪ§ЃЌБэЪОВЂВЛжБНгЩшЖЈБЃСєЕФжїГЩЗнЮЌЪ§ЃЌЖјЪЧЩшЖЈБЃСєЕФжїГЩЗнгІТњзуЦфЗНВюКЭеМБШ >0.9ЁЃ
3.3 ИФНјЫуЗЈЃКдіСПжїГЩЗжЗжЮіЃЈdecomposition.IncrementalPCAЃЉ
ЁЁЁЁЖдгкбљБОМЏОоДѓЕФЮЪЬтЃЌР§ШчбљБОСПДѓгк 10ЭђЁЂЬиеїБфСПДѓгк100ЃЌPCA ЫуЗЈКФЗбЕФФкДцКмДѓЃЌЩѕжСЮоЗЈДІРэЁЃЁЁЁЁЁЁ
ЁЁЁЁclass sklearn.decomposition.IncrementalPCA РрЪЧдіСПжїГЩЗжЗжЮіЫуЗЈЕФОпЬхЪЕЯжЃЌЙйЭјНщЩмЯъМћЃКhttps://scikit-learn.org/stable/modules/generated/sklearn.decomposition.IncrementalPCA.html
ЁЁ
class sklearn.decomposition.IncrementalPCA(n_components=None, *, whiten=False, copy=True, batch_size=None)
ЁЁЁЁжївЊВЮЪ§ЃК
inverse_transform()ЁЁЁЁНЋНЕЮЌКѓЕФЪ§ОнзЊЛЛГЩдЪМЪ§Он
ЁЁЁЁIncrementalPCA ЕФЪЙгУР§ГЬШчЯТЃК
# Demo of sklearn.decomposition.IncrementalPCA
from sklearn.datasets import load_digits
from sklearn.decomposition import IncrementalPCA, PCA
from scipy import sparse
X, _ = load_digits(return_X_y=True)
print(type(X)) # <class 'numpy.ndarray'>
print(X.shape) # (1797, 64)
modelPCA = PCA(n_components=6) # НЈСЂФЃаЭЃЌЩшЖЈБЃСєжїГЩЗжЪ§ K=6
modelPCA.fit(X) # гУЪ§ОнМЏ X бЕСЗ ФЃаЭ modelPCA
print(modelPCA.n_components_) # ЗЕЛи PCA ФЃаЭБЃСєЕФжїГЩЗнИіЪ§
# 6
print(modelPCA.explained_variance_ratio_) # ЗЕЛи PCA ФЃаЭИїжїГЩЗнеМБШ
# [0.1489 0.1362 0.1179 0.0841 0.0578 0.0492]
print(sum(modelPCA.explained_variance_ratio_)) # ЗЕЛи PCA ФЃаЭИїжїГЩЗнеМБШ
# 0.5941
print(modelPCA.singular_values_) # ЗЕЛи PCA ФЃаЭИїжїГЩЗнЕФЦцвьжЕ
# [567.0066 542.2518 504.6306 426.1177 353.3350 325.8204]
# let the fit function itself divide the data into batches
Xsparse = sparse.csr_matrix(X) # бЙЫѕЯЁЪшОиеѓЃЌВЂЗЧ IPCA ЕФБивЊВНжш
print(type(Xsparse)) # <class 'scipy.sparse.csr.csr_matrix'>
print(Xsparse.shape) # (1797, 64)
modelIPCA = IncrementalPCA(n_components=6, batch_size=200)
modelIPCA.fit(Xsparse) # бЕСЗФЃаЭ modelIPCA
print(modelIPCA.n_components_) # ЗЕЛи PCA ФЃаЭБЃСєЕФжїГЩЗнИіЪ§
# 6
print(modelIPCA.explained_variance_ratio_) # ЗЕЛи PCA ФЃаЭИїжїГЩЗнеМБШ
# [0.1486 0.1357 0.1176 0.0838 0.0571 0.0409]
print(sum(modelIPCA.explained_variance_ratio_)) # ЗЕЛи PCA ФЃаЭИїжїГЩЗнеМБШ
# 0.5838
print(modelIPCA.singular_values_) # ЗЕЛи PCA ФЃаЭИїжїГЩЗнЕФЦцвьжЕ
#[566.4544 541.334 504.0643 425.3197 351.1096 297.0412]
БОР§ГЬЕїгУСЫ SKlearnФкжУЕФЪ§ОнМЏ .datasets.load_digitsЃЌВЂИјГіСЫ PCA ЫуЗЈгы IPCA ЫуЗЈЕФЖдБШЃЌСНжжЫуЗЈЕФНсЙћЗЧГЃНгНќЃЌЫЕУї IPCA ЕФадФмНЕЕЭКмаЁЁЃ
3.4 ИФНјЫуЗЈЃККЫжїГЩЗжЗжЮіЃЈdecomposition.KernelPCAЃЉ
ЖдгкЯпадВЛПЩЗжЕФЪ§ОнМЏЃЌЪЙгУЗЧЯпадЕФКЫКЏЪ§ПЩвдАббљБОПеМфгГЩфЕНЯпадПЩЗжЕФИпЮЌПеМфЃЌШЛКѓдкетИіИпЮЌПеМфНјаажїГЩЗжЗжЮіЁЃ
class sklearn.decomposition.KernelPCA РрЪЧЫуЗЈЕФОпЬхЪЕЯжЃЌЙйЭјНщЩмЯъМћЃКhttps://scikit-learn.org/stable/modules/generated/sklearn.decomposition.KernelPCA.html
ЁЁЁЁ
class sklearn.decomposition.KernelPCA(n_components=None, *, kernel='linear', gamma=None, degree=3, coef0=1, kernel_params=None, alpha=1.0, fit_inverse_transform=False, eigen_solver='auto', tol=0, max_iter=None, remove_zero_eig=False, random_state=None, copy_X=True, n_jobs=None)
KernelPCA ЕФЪЙгУР§ГЬШчЯТЃК
# Demo of sklearn.decomposition.KernelPCA
from sklearn.datasets import load_iris
from sklearn.decomposition import KernelPCA, PCA
import matplotlib.pyplot as plt
import numpy as np
X, y = load_iris(return_X_y=True)
print(type(X)) # <class 'numpy.ndarray'>
modelPCA = PCA(n_components=2) # НЈСЂФЃаЭЃЌЩшЖЈБЃСєжїГЩЗжЪ§ K=2
Xpca = modelPCA.fit_transform(X) # гУЪ§ОнМЏ X бЕСЗ ФЃаЭ modelKPCA
modelKpcaP = KernelPCA(n_components=2, kernel='poly') # НЈСЂФЃаЭЃЌКЫКЏЪ§ЃКЖрЯюЪН
XkpcaP = modelKpcaP.fit_transform(X) # гУЪ§ОнМЏ X бЕСЗ ФЃаЭ modelKPCA
modelKpcaR = KernelPCA(n_components=2, kernel='rbf') # НЈСЂФЃаЭЃЌКЫКЏЪ§ЃКОЖЯђЛљКЏЪ§
XkpcaR = modelKpcaR.fit_transform(X) # гУЪ§ОнМЏ X бЕСЗ ФЃаЭ modelKPCA
modelKpcaS = KernelPCA(n_components=2, kernel='cosine') # НЈСЂФЃаЭЃЌКЫКЏЪ§ЃКгрЯвКЏЪ§
XkpcaS = modelKpcaS.fit_transform(X) # гУЪ§ОнМЏ X бЕСЗ ФЃаЭ modelKPCA
fig = plt.figure(figsize=(8,6))
ax1 = fig.add_subplot(2,2,1)
ax2 = fig.add_subplot(2,2,2)
ax3 = fig.add_subplot(2,2,3)
ax4 = fig.add_subplot(2,2,4)
for label in np.unique(y):
position = y == label
ax1.scatter(Xpca[position, 0], Xpca[position, 1], label='target=%d' % label)
ax1.set_title('PCA')
ax2.scatter(XkpcaP[position, 0], XkpcaP[position, 1], label='target=%d' % label)
ax2.set_title('kernel= Poly')
ax3.scatter(XkpcaR[position, 0], XkpcaR[position, 1], label='target=%d' % label)
ax3.set_title('kernel= Rbf')
ax4.scatter(XkpcaS[position, 0], XkpcaS[position, 1], label='target=%d' % label)
ax4.set_title('kernel= Cosine')
plt.suptitle("KernalPCA")
plt.show()
БОР§ГЬЕїгУСЫ SKlearnФкжУЕФЪ§ОнМЏ .datasets.load_irisЃЌВЂИјГіСЫ PCA ЫуЗЈгы 3жжКЫКЏЪ§ЕФKernelPCA ЫуЗЈЕФЖдБШЃЌНсЙћШчЯТЭМЫљЪОЁЃВЛЭЌЫуЗЈЕФНЕЮЌКѓгГЩфЕНЖўЮЌЦНУцЕФНсЙћгаВювьЃЌНјвЛВНЕФЬжТлвбОГЌГіБОЮФЕФФкШнЁЃ
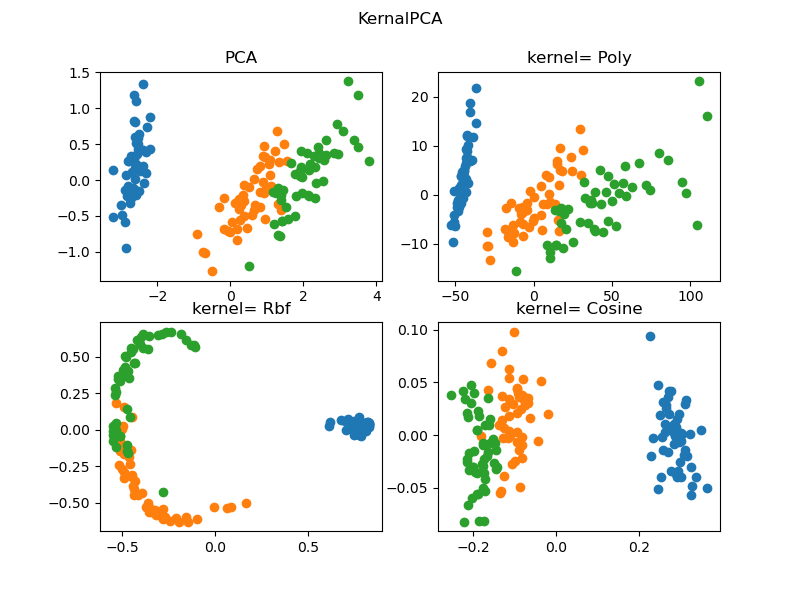
АцШЈЫЕУїЃК
БОЮФФкШнМАР§ГЬЮЊзїепдДДЃЌВЂЗЧзЊдиЪщМЎЛђЭјТчФкШнЁЃ
БОЮФжаАИР§ЮЪЬтРДздЃК
1 SciKit-learn ЙйЭјЃКhttps://scikit-learn.org/stable/index.html
YouCans дДДзїЦЗ
Copyright 2021 YouCans, XUPT
CratedЃК2021-05-10
bk