1 背景
2020年工作上的最大收获就是初步完善了系统的监控告警体系。
2020年工作上可谓是非常苦逼的,项目上忙到脚打后脑勺的同时还被各种发布问题、生产故障按在地上摩擦。可怜还因疫情原因公司福利大大缩减。
总结了一下令人头疼的问题:
- 每次大的发布总会产生一堆的生产问题
- 日常应用出错不能第一时间感知,总是到了客户那里才报过来
比如有一次发布后产生了一个小小的传值问题,但是会阻碍一部分客户下单,结果两天后通过客户报障才发现,最终导致大量订单损失!
总体来讲就是缺乏对系统的掌控,应用发布上去后,就像个黑匣子,你只知道它在运行,却不知道里面到底是个什么状况,也许内部已经乱的不可开交,你却一无所知,发布之后只留下一脸懵逼的你独自凌乱。以致于每次发布后的几天都是提心吊胆,有点风吹草动就慌得一比!而在互联网这个频繁发布的行业简直就是灾难
痛定思痛!终于在下半年的时候忍无可忍,决定给系统插上X光机。不仅要扒掉系统这个“美女”的黑色外衣,甚至让其骨骼线条都赤裸裸的暴露在开发人员眼中。这个X光机就是监控告警体系。
2 技术方案
我们所使用的是公司自研的监控系统。其大致实现如下图:
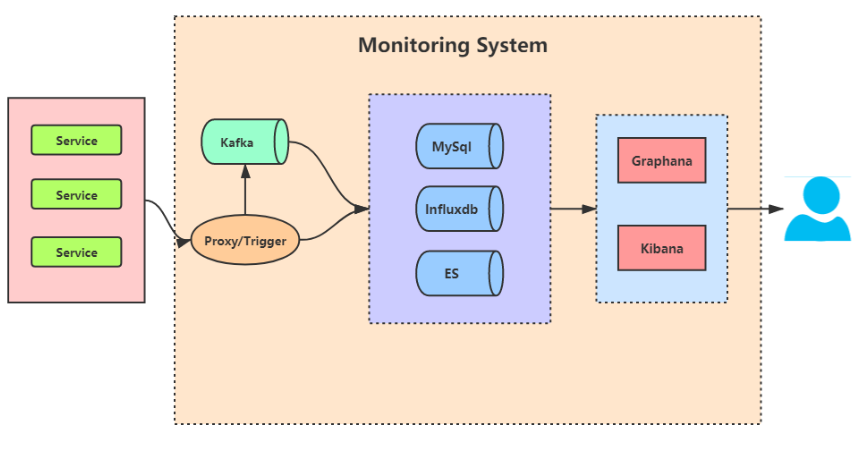
- 各应用系统通过代理客户端写入Kafka
- 持久化层服务订阅Kafka消息进行持久化,这其中Influxdb主要存储时序埋点,MySql与ES存储点的一些特性方便检索与聚合
- UI层读取展示埋点信息,监控告警配置,主要借助两个强大的可视化工具,Grafana与Kibana。
实现监控告警体系其实就分3步:
- 应用系统埋点
- 可视化展示
- 监控告警配置
最简单的方式可以通过 ES+Kibana的方案来实现
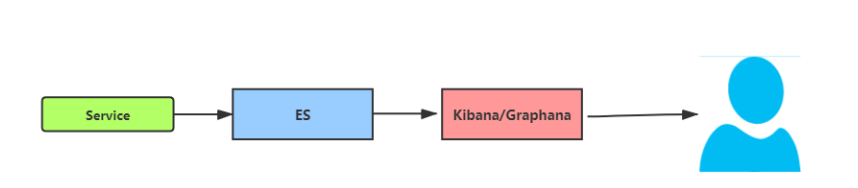
注意;在系统没有遇到瓶颈的时候应该尽可能的用最简单的方案解决问题,每引入一个中间件便大大增加了系统的复杂度和维护成本
3 监控内容
技术上的实现,其实只是监控体系的第一步。最重要的部分在于监控的内容,只有做好了监控内容才算是给你的系统构建了一个良好的监控大网。而监控哪些内容,不同的系统,不同的业务需求都不相同,这就需要根据业务与系统的要求去制定与不断的完善。
根据我们的经验总结了几个通用的监控点
- 请求量
请求量不仅可以用来统计接口调用的数量、QPS等信息,还可以发现系统的问题。
这里请求量主要包含两部分,一个是你自己提供的接口的请求量,一部分是你所依赖接口的请求量
- 如果你自己提供的接口的请求量突然下降,那么说明依赖你接口的下游应用、或是前置页面极有可能除了问题。
- 而如果你自己接口的请求量正常,而所调用的第三方接口的请求量突然下降,那么极有可能你自己的代码逻辑除了问题
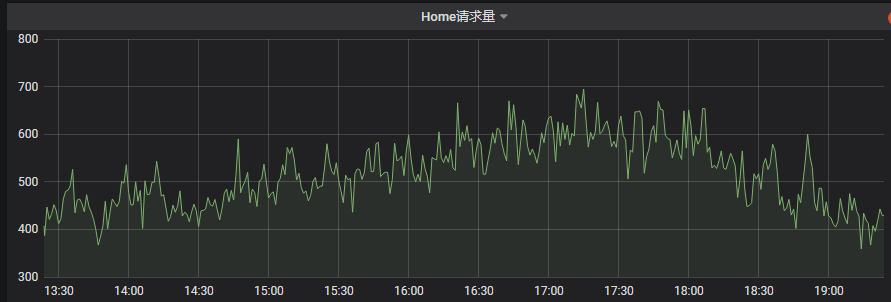
请求量一般通过曲线图展示,可以更好的反映出来一个趋势。
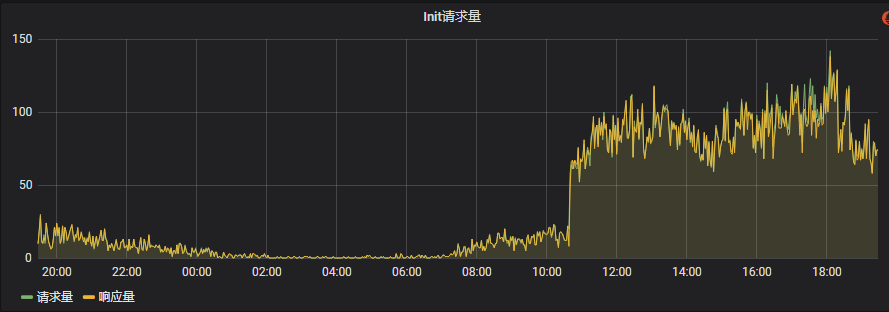
- 响应量
响应量通常可以和请求量结合使用,如果一个接口正常响应量小于请求量,那么说明有一部分的请求是存在问题的。
- 耗时
接口耗时主要用来监控接口性能,同样包括你自己提供的接口的耗时和你所依赖的接口耗时。
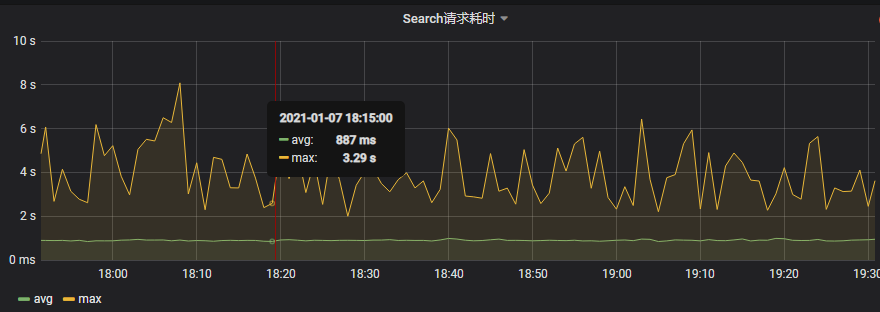
- 订单量
在许多系统中,订单量都是一个很重要的业务指标,也是我们最重要的监控指标之一。
- 响应状态
响应状态是一个很好的监控指标,它能够很好的反映我们程序的处理结果。响应状态比较适合用饼图来展示。可以很好的反映出各种状态的占比。
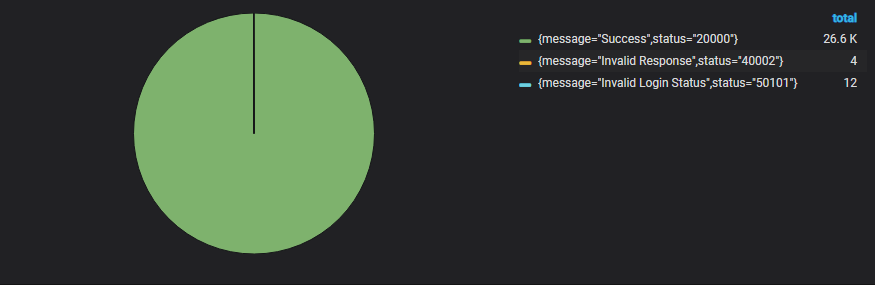
- 异常状态
同响应状态一样,异常状态的监控也具有很重要的意义。同时异常状态也是我们用户告警的重要指标之一,他可以很直观的反映出我们系统的健康状态,异常状态可以用饼图,也可以用曲线图来展示。
- 页面之间转化率
页面之间转化率不仅仅是用户衡量产品价值的指标,同样是我们系统监控的重要指标,如果从一个页面到另一个页面的转化率突然降低,那么极有可能是这之间出现了什么问题。
- 其它
还有很多针对具体业务的监控指标,如搜索通常会有空搜率,商品会有缺货率。。。
当然,可能还有很多不足,也可能随着业务需求的变化,有些监控内容可能已经过时,又可能会需要更多监控,
这里只提供一些思路,总之针对业务上的各种场景你可以尽情去做到一切皆埋点。
4 告警策略
监控内容最好之后,监控体系并没有结束,还差一步,就是自动告警。自动告警的功能Grafana和Kibana都可以提供,也可以自定义我们想要的告警方式。
这里我们主要的告警策略主要有三种
- 阈值
我们可以对请求量、订单量、异常量设定一个阈值,当每分钟每小时请求量下降到某个阈值,或者异常量达到某个阈值的时候,触发我们的告警。
- 环比
环比主要是与前一段时间的对比,比如这一小时(或一天)的请求量与上一小时(或一天)的请求量对比,如果小于如果小于某个阈值,就触发我们的告警。
- 同比
有些时候环比是不可靠的,比如,我们系统的特性就是周二、周三、周四的请求量要远大于周五、周六、周天的请求量,此时如果拿周六的请求量和周五的请求量的去对比是没有意义的,这里就需要用到同比,即拿上周五的请求量和本周五的请求量进行对比,当小于某个阈值的时候触发告警。
注意:这里的告警和阈值并非可以一蹴而就的,需要结合实际去慢慢调整它到一个合适的值,我们就深感其痛。(起初就因为一些不合理的告警配置,我们优秀的人工智能经常三更半夜给打你电话,结果通常是虚惊一场,它还比较轴,你不处理它就一直打)。
5 监控成果
历时半年,我们对系统的监控告警体系的打造总算是告一段落。俗话说要想吃多少肉,就要先挨多少揍。这期间过程虽然是辛苦的,但成果也是巨大的。之前的问题得到了良好的解决。大部分的线上问题,第一时间就暴露了出来,有些问题在测试环境上通过监控就提早发现。这也侧面的助力我们的测试工作。甚至在监控体系上线后一些“陈年”老bug也开始暴露出来。生产事件率大幅下降。
最重要的是每个开发人员对系统多了一种掌控的感觉,期待有一天,一群苦逼了许久的程序员可以在今后的每次发布后,轻松看着监控大盘,喝茶扯淡!