������������˸�ʽ����ӽ�����С���ɣ������������ip�Σ�����Լ�д���ű�����hosts.cfg�ļ���Ϊ���Ժ�ά�����㣬���������ļ���ʹ������ע�ͣ��籾��# Wangjing IDC servers #����
��һ���������������ļ���services.cfg,û������ļ���ʲô���Ҳû�á��������һ����ʽ�ļ���
#service definition
##############################################################
# Wangjing IDC servers service for host-live #
##############################################################
define service {
host_name nagios-server //��Դ��hosts.cfg
service_description check-host-alive
check_period 24x7
max_check_attempts 4
normal_check_interval 3
retry_check_interval 2
contact_groups sagroup //��Դ��contactgroups.cfg
notification_interval 10
notification_period 24x7
notification_options w,u,c,r
check_command check-host-alive //��������Ƿ���
}
define service {
host_name 74-210
service_description check_tcp 80
check_period 24x7
max_check_attempts 4
normal_check_interval 3
retry_check_interval 2
contact_groups sagroup
notification_interval 10
notification_period 24x7
notification_options w,u,c,r
check_command check_tcp!80 //���tcp 80�˿ڷ����Ƿ�����
} |
��дʱҪע����ǣ�check_tcp��Ҫ��صķ���˿�֮��Ҫ�á�!�����ָ������������̫�࣬��Ӧ�ÿ����ýű������ɡ�
�����������ļ�hostgroups.cfg������һ����ѡ����Ŀ�����������ļ�hosts֮�ϣ����ʽ���£�
define hostgroup {
hostgroup_name sa-servers
alias sa servers
members nagios-server,24-25,24-26 //�ö��ż���������
} |
���������������ĸ�ʽ�������ȥ�������һ��������Ľ�ͼ��
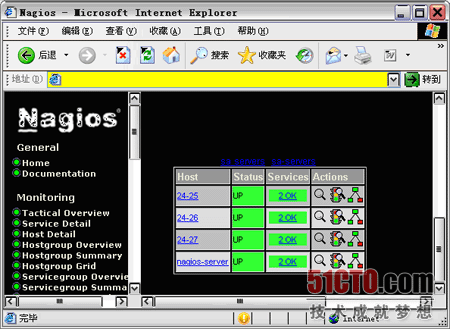
ǧ����࣬���ڰ���Щ���ø����ñ��棬���ڼ����е��Ȳ������ˣ����г���/usr/local/nagios �Cv /usr/local/nagios/etc/nagios.cfg��������������ļ�����ȷ�ԡ����ʮ�����˵Ļ���������Ͻ������β�����֣�
Total Warnings: 0
Total Errors: 0
Things look okay - No serious problems were detected during the pre-flight check
|
�������������ɣ�����ȴû����ô���ˣ����˺ö���ط��ųɹ�������ֵ�����ҵ��ǣ����У��Ĵ���ʱ�dz����õģ������е�ϵͳ�İ����ĵ��п������ã������ҹ������õ�һ����������������